เมื่อคืนก่อนตอนเที่ยงคืน ผมสะดุ้งตื่นเพราะได้ยินเสียงสัญญาณกันขโมย ก็เลยลุกงัวเงียเดินไปแง้มหน้าต่างเพื่อดูว่ารถตูหรือเปล่าวะ, อ้าวฉิบหายแล้ว รถเรานี่เอง ตอนนั้นสิ่งที่นึกในหัวก็คือ "เอาอีกแล้วไอ้เจ้าสัญญาณกันขโมยเฮงซวย" ที่คิดอย่างนั้นก็เพราะช่วงหลังๆ สัญญาณกันขโมยผมมันชอบร้องโวยวายโดยไม่มีสาเหตุ ร้องจนผมเลิกล็อครถตอนจอดอยู่ในบ้านแล้ว
หลังจากรู้ว่ารถตัวเองแน่นอน ก็เลยรีบวิ่งลงไปข้างล่างเพื่อไปหากุญแจมาปิดสัญญาณ(ไม่อยากให้เพื่อนบ้านหนวกหู) แต่ค้นเท่าไรก็ไม่เจอ อารมณ์โมโหเริ่มครอบงำ นึกกล่าวโทษภรรเมียว่าเก็บกุญแจไม่เป็นที่เป็นทาง
ตอนที่เดินหากุญแจในอยู่ ก็พบว่า อ้าวตู้เนี่ยทำไมเปิดอยู่ จัดการปิดซะเดินไปหาถึงประตูหลัง อ้าวประตูเปิดอยู่ นึกในใจ เด็กทำงานบ้านเราทำไมมันชุ่ยอย่างนี้ ไม่ยอมปิดประตูก่อนนอน ว่าแล้วก็ปิดประตูซะ ผ่านไปพักใหญ่สัญญาณก็หยุดทำงาน ก็เลยหยุดหาแล้วก็เปิดประตูหน้าบ้านออกไปดูว่าเกิดอะไรขึ้น พอหมุนลูกบิดก็รู้สึกว่า อ้าวประตูไม่ได้ล็อก ดูเสร็จไม่พบอะไรก็ล็อกซะ
ตอนนั้นก็ไม่เอะใจอะไร เดินไปปลุกแฟน เอากุญแจไปซ่อนไว้ที่ไหนหามาให้เดี๋ยวนี้นะ
แฟนก็บอกว่าไม่ได้เอาไป แล้วก็เดินลงมาช่วยหา ซึ่งก็หาไม่เจออีก แฟนก็เลยเดินขึ้นไปปลุกเด็กที่ทำงานบ้าน เด็กก็บอกว่าไม่ได้เอาไป
เท่านั้นเอง ผมก็ตาสว่างร้อง Eureka!! ขโมยขึ้นบ้านกูนี่หว่า ว่าแล้วก็ลงไปสำรวจหลังบ้าน ก็ได้พบกุญแจรถยนต์สมใจ (ขโมยมันโยนทิ้งไว้)
เรื่องที่อยากเล่าให้ฟังจริงๆก็คือ วิธีการทำงานของสมองเรา สิ่งที่เราคิดเราเชื่อจะเป็นตัวกำหนดกรอบความคิดของเรา เมื่อเกิด event หนึ่งๆขึ้น สมองเราก็จะใช้เส้นทางที่มันถนัดที่สุดในการตีความ event นั้นๆ
ซึ่งการด่วนตัดสิน(ฟันธง, confirm) ก็จะทำให้เราพลาดการมองเห็นสิ่งที่เกิดขึ้นจริงๆ
ยิ่งเราแก่ตัวลง ถ้าเรายึดมั่นในชุดความคิดใดความคิดหนึ่งมากๆ การคิดบ่อยๆเชื่อบ่อยๆ ก็จะยิ่งย้ำเส้นทางของ Neural network ในสมองเราให้เชื่อมกันแนบแน่นยิ่งขึ้น นี่เป็นสาเหตุที่เรามักพบว่า คนแก่มักจะหัวดื้อและไม่ยอมฟัง
นึกเปรียบเทียบกับสภาพบ้านเมืองตอนนี้ ขโมยขึ้นบ้าน(ภาวะเศรษฐกิจโลก) แต่เรายังหมกมุ่นกับเรื่องกุญแจไม่เลิก (แทนคำว่ากุญแจกันเอาเองนะ แทนได้หลายคำเลย)
Tuesday, December 23, 2008
Monday, December 08, 2008
random เรียกชื่อคน
เมื่อสุดสัปดาห์ที่ผ่านมาผมมีภาระกิจต้องไปสัมมนากับบริษัทฯ โดยในสัมมนาผมต้องนำคุยทำความรู้จักกับนิยามของ Knowledge แต่เนื่องจากเรื่องนี้มันคลุมเครือและออกนามธรรมมาก การที่น้องๆจะสมัครใจแสดงความคิดเห็น คงจะยากมาก ประกอบกับพึ่งอ่าน blog ของอาจารย์ cholwich ซึ่งเขียนโปรแกรม random ชื่อนักเรียนด้วย java ก็เลยลอกวิธีการมาใช้บ้าง แต่เนื่องจากช่วงนี้กำลังอินกับ clojure ก็เลย implement ด้วย clisp
ลองมาดูตัวโปรแกรมกัน
เริ่มจากการกำหนด global variable สำหรับเก็บชื่อคน
ตามด้วยการกำหนดชื่อคน
Note: global variable ใน clisp มี scope แบบ dynamic, การตั้งชื่อนิยมตั้งด้วย * นำหน้า เพื่อให้แยกความแตกต่างจาก local variable เพราะถ้าตั้งชื่อตรงกันอาจจะเจอปัญหาการ binding ได้
จากนั้นก็สร้าง function ที่ random ชื่อออกมา
ส่วน
โปรแกรมก็ทำงานได้ดี แต่ใช้ไปนานๆ มัน random คนออกมาซ้ำๆกันมากไปหน่อย
กลับมาจากสัมมนาแล้ว ก็เลยมานั่งปรับปรุงให้มันเอาชื่อคนที่เคยเรียกแล้วออกไปจาก list ให้ด้วย (จะได้ไม่เรียกซ้ำ)
สุดท้ายก็ปรับปรุงว่า ถ้าเอาชื่อออกจนหมดแล้ว ก็ให้ reset รายชื่อใหม่
ลองมาดูตัวโปรแกรมกัน
เริ่มจากการกำหนด global variable สำหรับเก็บชื่อคน
(defvar *names*)
ตามด้วยการกำหนดชื่อคน
(setq *names* '(pok bunny pann pune))
Note: global variable ใน clisp มี scope แบบ dynamic, การตั้งชื่อนิยมตั้งด้วย * นำหน้า เพื่อให้แยกความแตกต่างจาก local variable เพราะถ้าตั้งชื่อตรงกันอาจจะเจอปัญหาการ binding ได้
จากนั้นก็สร้าง function ที่ random ชื่อออกมา
(defun next ()
(nth (random (length *names*)) *names*))
nth คือ function ที่ใช้ access list ที่ตำแหน่ง index ที่ต้องการส่วน
(random N) จะได้ค่า integer ระหว่าง 0 ถึง (N-1)โปรแกรมก็ทำงานได้ดี แต่ใช้ไปนานๆ มัน random คนออกมาซ้ำๆกันมากไปหน่อย
กลับมาจากสัมมนาแล้ว ก็เลยมานั่งปรับปรุงให้มันเอาชื่อคนที่เคยเรียกแล้วออกไปจาก list ให้ด้วย (จะได้ไม่เรียกซ้ำ)
(defun next ()
(let ((name (nth (random (length *names*)) *names*)))
(setq *names* (remove name *names*))
name))
สุดท้ายก็ปรับปรุงว่า ถ้าเอาชื่อออกจนหมดแล้ว ก็ให้ reset รายชื่อใหม่
(defun next ()
(if (null *names*)
(setq *names* '(pok bunny pann pune)))
(let ((name (nth (random (length *names*)) *names*)))
(setq *names* (remove name *names*))
name))
Related link from Roti
Tuesday, December 02, 2008
เรียนรู้ Clojure ตอน tail recusive
recursive คือหัวใจหลักของภาษาตระกูล functional, ตัว runtime ของภาษาตระกูลนี้ต้องออกแบบมาให้สามารถทำ optimize tail recursive เพื่อหลีกเลี่ยง stack overflow. โชคร้ายที่ jvm ไม่ได้ออกแบบมาเพื่อทำ optimize แบบนั้น (ยกเว้น IBM JVM - Java กับ Tail-Recursive)
เจ้า closure ก็เลยต้องอาศัย syntax พิเศษเพื่อเลียนการทำงานแบบ tail recursive
ลองดูตัวอย่าง code จริง
keyword จะอยู่ที่ loop กับ recur นี่แหล่ะ
loop เป็น syntax แบบเดียวกับ let แต่มันจะกำหนดจุดที่จะเกิดการ recursion
ส่วน recur เป็นการสั่งให้กระโดดกลับไปทำงานที่ loop อีกครั้ง แต่จะมีการเปลี่ยน binding ของตัวแปรที่กำหนดไว้ตอนประกาศ loop
ลองดูตัวอย่างข้างล่าง ซึ่งเป็นการหาค่า factorial โดยใช้วิธี recursive แบบ pass ค่า accumulator
จะเห็นว่าที่ตำแหน่ง loop มีการกำหนด binding ตัวแปร cnt กับ acc
ดังนั้นเมื่อถึงตอนสั่ง recur ก็จะต้องส่ง parameter ที่จะเป็นค่าใหม่ของ cnt และ acc กลับมาด้วย
เปรียบเทียบกับการเขียนแบบ recursive ใน clisp ก็จะเป็นแบบนี้
หลังจากที่ Clojure ออกมา ก็มีคนถามประเด็น mutual recursive ว่าจะเขียนอย่างไร
ลองดูตัวอย่าง mutual recursive ก่อน
Note: code แบบข้างบนนี้ ถ้าไปเขียนใน clisp จะ run ได้โดย stack ไม่ overflow
Rich Hickey ก็เลยแก้ code ของ clojure โดยใช้ technique ที่เรียกว่า trampoline
syntax ของ foo bar ข้างบนก็เลยต้องเขียนแบบนี้แทน
เจ้า closure ก็เลยต้องอาศัย syntax พิเศษเพื่อเลียนการทำงานแบบ tail recursive
ลองดูตัวอย่าง code จริง
(defn render-level-layer
"my, what an insane level representation i have here"
[target items if-empty if-full]
(loop [target target
remain (seq items)]
(if remain
(let [x (:x (first remain))
y (:y (first remain))
i (level-index x y)
at (target i)]
(recur (assoc target i (if (= at \space) if-empty if-full))
(rest remain)))
target)))
keyword จะอยู่ที่ loop กับ recur นี่แหล่ะ
loop เป็น syntax แบบเดียวกับ let แต่มันจะกำหนดจุดที่จะเกิดการ recursion
ส่วน recur เป็นการสั่งให้กระโดดกลับไปทำงานที่ loop อีกครั้ง แต่จะมีการเปลี่ยน binding ของตัวแปรที่กำหนดไว้ตอนประกาศ loop
ลองดูตัวอย่างข้างล่าง ซึ่งเป็นการหาค่า factorial โดยใช้วิธี recursive แบบ pass ค่า accumulator
จะเห็นว่าที่ตำแหน่ง loop มีการกำหนด binding ตัวแปร cnt กับ acc
ดังนั้นเมื่อถึงตอนสั่ง recur ก็จะต้องส่ง parameter ที่จะเป็นค่าใหม่ของ cnt และ acc กลับมาด้วย
(def factorial
(fn [n]
(loop [cnt n
acc 1]
(if (zero? cnt)
acc
(recur (dec cnt) (* acc cnt))))))
เปรียบเทียบกับการเขียนแบบ recursive ใน clisp ก็จะเป็นแบบนี้
(defun factorial (n &optional (acc 1))
(if (<= n 1)
acc
(factorial (- n 1) (* acc n))))
หลังจากที่ Clojure ออกมา ก็มีคนถามประเด็น mutual recursive ว่าจะเขียนอย่างไร
ลองดูตัวอย่าง mutual recursive ก่อน
(declare bar)
(defn foo [n]
(if (pos? n)
(bar (dec n))
:done-foo))
(defn bar [n]
(if (pos? n)
(foo (dec n))
:done-bar))
(foo 1000000)
-> java.lang.StackOverflowError
Note: code แบบข้างบนนี้ ถ้าไปเขียนใน clisp จะ run ได้โดย stack ไม่ overflow
Rich Hickey ก็เลยแก้ code ของ clojure โดยใช้ technique ที่เรียกว่า trampoline
instead of actually making a call in the tail, a function returns the function to be called, and a controlling loop calls it
syntax ของ foo bar ข้างบนก็เลยต้องเขียนแบบนี้แทน
(declare bar)
(defn foo [n]
(if (pos? n)
#(bar (dec n))
:done-foo))
(defn bar [n]
(if (pos? n)
#(foo (dec n))
:done-bar))
Related link from Roti
Monday, November 24, 2008
google กับ *
วันนี้เล่น clojure แล้ว search หาตัวอย่างการใช้ fn* ใน google
ปรากฎว่าการใส่ * ในช่อง text ที่ใช้ search กลายเป็นการ enable feature searchwiki ไป
ดูตัวอย่าง
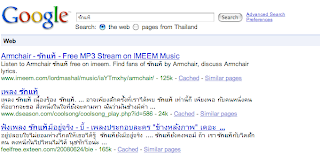
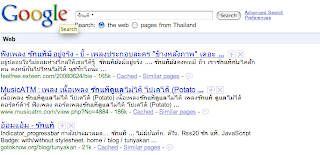
ปรากฎว่าการใส่ * ในช่อง text ที่ใช้ search กลายเป็นการ enable feature searchwiki ไป
ดูตัวอย่าง


Related link from Roti
เรียนรู้ Clojure ตอนที่ 3
Clojure ประกาศตัวชัดเจนว่า มันไม่ได้เป็น OOP (ถึงแม้จะ run อยู่บน platform ที่เป็น OOP จ๋าแบบ Java)
และเลือกข้าง functional อย่างชัดเจน (ไม่เหมือน scala ที่เลือกมันสองข้างเลย)
มาลองดู code ที่ตัดมาจากตัวอย่าง code ในตอนที่ 1
เริ่มด้วยบรรทัดบนสุด เป็นการระบุ namespace (ถ้าเทียบกับ java ก็คือ package)
บรรทัดที่สองบอกด้วยว่าให้ import class java.util.regex.Pattern เข้ามาด้วย
(note: ใน clojure มันมี syntax สำหรับ regex ให้ใช้เหมือนกัน แต่คนเขียนเลือกใช้แบบเรียกผ่าน java)
มาดู function line-explode ก่อน
จะเห็นเขาประกาศ function ด้วย form แบบนี้
โปรแกรมตระกูล lisp นี่, ตัว code ก็เป็น data structure ด้วย
ดังนั้นจะเห็นว่า params ก็คือ vector type, ส่วน body เป็น list type
จาก code จะเห็นว่า function explode รับ parameter ตัวเดียว ก็คือ lines
ตัว body ของ function line-explode จะอยู่ในรูป let syntax
ลองดู bindings ของโปรแกรมตัวอย่าง
ถ้าเทียบกับ java แล้วบรรทัดข้างบนก็คือ
ที่นี้ก็มาถึง body ของ function line-explode
เวลาอ่านก็ให้ไล่จากในออกมาข้างนอก
เริ่มจากในสุด
ก็คือการเรียกใช้ method split บน Pattern instance (ในที่นี้ก็คือการตัดที่ตำแหน่ง new-line)
ตรงนี้เขา show ความสามารถของ infinite-sequence และ lazy behavior ของ Clojure
โดยผลลัพท์ที่ได้จะ เป็นไปตามกฎนี้
สมาชิกตัวแรกของผลลัพท์เกิดจากการเรียกใช้ (inc 0) ซึ่งจะได้ผลลัพท์เป็น 1
ผลลัพท์ตัวที่สองเกิดจากการเรียกใช้ (inc ผลลัพท์ตัวแรก) ซึ่งก็คือ (inc 1)
ผลลัพท์ตัวถัดๆไปก็คือ (inc ผลลัพท์ตัวก่อนหน้ามัน)
ดังนั้น (iterate inc 0) จะได้ผลลัพท์เป็น (1 2 3 4 5 6 ... infinity)
ส่วน function map นี้ เดี๋ยวนี้นิยมใช้กันมากแล้ว คงไม่ต้องอธิบาย
แต่ว่า map ของพวก lisp นี้เขารับ collection ได้หลาย collection พร้อมๆกัน
ลองดูตัวอย่างนี้
เนื่องจากเจ้า map function มันไปเรียกใช้ function
ใน code ข้างบนจะเห็นว่ามี
นั่นคือมันจะจับ ตัวแปร ณ scope ที่มันถูกประกาศ
ตัว
ดูจาก code แล้วจะเห็นว่า function
ทดลอง run ดู
กลับมาที่ line-explode, function ตัวสุดท้ายก็คือ
reduce รับ parameter เป็น function และ list
โดยมันจะเรียก function โดยมี parameter เป็นสมาชิกตัวที่ 1 และ 2 ของ list
จากนั้นก็จะเรียก function โดยมี parameter ตัวที่เป็นผลลัพท์ที่ได้จากครั้งก่อน กับ สมาชิกตัวที่ 3
ทำเช่นนี้ไปเรื่อยๆจนกว่าจะหมด
ส่วน
มันคือ operation ที่จับ array บวกกันนั่นเอง
สรุปแล้วจะเห็นว่าการ explode ก็คือการเปลี่ยน multi-line string ให้อยู่ในรูปของ [(pos x y) char] นั่นเอง
และเลือกข้าง functional อย่างชัดเจน (ไม่เหมือน scala ที่เลือกมันสองข้างเลย)
มาลองดู code ที่ตัดมาจากตัวอย่าง code ในตอนที่ 1
(ns test
(:import (java.util.regex Pattern)))
(defstruct pos :x :y)
(defn explode
"return a pos/type seq for each char in the line"
[y line]
(map (fn [x y type] (vector (struct pos x y) type))
(iterate inc 0) (repeat y) line))
(defn line-explode
"call explode on each line with the appropriate y"
[lines]
(let [linesplit (. Pattern compile "\n" (. Pattern MULTILINE))] ; must be a better way?
(reduce into
(map explode
(iterate inc 0)
(. linesplit split lines)))))
เริ่มด้วยบรรทัดบนสุด เป็นการระบุ namespace (ถ้าเทียบกับ java ก็คือ package)
(ns test
(:import (java.util.regex Pattern)))
บรรทัดที่สองบอกด้วยว่าให้ import class java.util.regex.Pattern เข้ามาด้วย
(note: ใน clojure มันมี syntax สำหรับ regex ให้ใช้เหมือนกัน แต่คนเขียนเลือกใช้แบบเรียกผ่าน java)
มาดู function line-explode ก่อน
จะเห็นเขาประกาศ function ด้วย form แบบนี้
(defn function-name description params body)
เข่น
(defn plus-9 "plus with 9" [x] (+ x 9))
โปรแกรมตระกูล lisp นี่, ตัว code ก็เป็น data structure ด้วย
ดังนั้นจะเห็นว่า params ก็คือ vector type, ส่วน body เป็น list type
จาก code จะเห็นว่า function explode รับ parameter ตัวเดียว ก็คือ lines
(defn line-explode
"call explode on each line with the appropriate y"
[lines]
ตัว body ของ function line-explode จะอยู่ในรูป let syntax
(let bindings body)
เช่น
(let [x 9, y 10] (+ x y))
run แล้วได้ผลลัพท์เป็น 19
ใน bindings ของ let นั้น, variable ที่ถูก bind ก่อน สามารถถูกอ้างถึงโดย variable ที่ bind ทีหลังได้
(let [x 9, y (+ x 7)] (+ x y))
run แล้วได้ผลลัพท์เป็น 25
ลองดู bindings ของโปรแกรมตัวอย่าง
(let [linesplit (. Pattern compile "\n" (. Pattern MULTILINE))] ; must be a better way?
ถ้าเทียบกับ java แล้วบรรทัดข้างบนก็คือ
Pattern linesplit = Pattern.compie("\n", Pattern.MULTILINE);
ที่นี้ก็มาถึง body ของ function line-explode
(reduce into
(map explode
(iterate inc 0)
(. linesplit split lines)))
เวลาอ่านก็ให้ไล่จากในออกมาข้างนอก
เริ่มจากในสุด
(. linesplit split lines)ก็คือการเรียกใช้ method split บน Pattern instance (ในที่นี้ก็คือการตัดที่ตำแหน่ง new-line)
(iterate inc 0)ตรงนี้เขา show ความสามารถของ infinite-sequence และ lazy behavior ของ Clojure
โดยผลลัพท์ที่ได้จะ เป็นไปตามกฎนี้
สมาชิกตัวแรกของผลลัพท์เกิดจากการเรียกใช้ (inc 0) ซึ่งจะได้ผลลัพท์เป็น 1
ผลลัพท์ตัวที่สองเกิดจากการเรียกใช้ (inc ผลลัพท์ตัวแรก) ซึ่งก็คือ (inc 1)
ผลลัพท์ตัวถัดๆไปก็คือ (inc ผลลัพท์ตัวก่อนหน้ามัน)
ดังนั้น (iterate inc 0) จะได้ผลลัพท์เป็น (1 2 3 4 5 6 ... infinity)
ส่วน function map นี้ เดี๋ยวนี้นิยมใช้กันมากแล้ว คงไม่ต้องอธิบาย
แต่ว่า map ของพวก lisp นี้เขารับ collection ได้หลาย collection พร้อมๆกัน
ลองดูตัวอย่างนี้
(map + '(1 2 3) '(3 4 5))
=> (4 6 8)
(map + '(1 2 3) '(3 4 5 6 7 8))
=> (4 6 8)
เนื่องจากเจ้า map function มันไปเรียกใช้ function
explode ดังนั้นเราต้องตามไปดูว่ามันทำอะไร
(defn explode
"return a pos/type seq for each char in the line"
[y line]
(map (fn [x y type] (vector (struct pos x y) type))
(iterate inc 0) (repeat y) line))
ใน code ข้างบนจะเห็นว่ามี
fn ในบรรทัดที่ 4 โดยมันคือการ define function อีกแบบหนึ่ง ซึ่งมีคุณสมบัติแบบ closure นั่นคือมันจะจับ ตัวแปร ณ scope ที่มันถูกประกาศ
test> (def foo
(let [y 10]
(fn [x] (+ x y))))
#=(var test/foo)
test> (foo 7)
17
ลองเปลี่ยน y ให้เป็น 12 ณ ขณะที่ run
test> (let [y 12] (foo 7))
17
ตัว
repeat นั่นเป็น infinite list อีกตัวหนึ่ง(repeat 7)
=> (7 7 7 7 7 7 7 7 7 .....)
ดูจาก code แล้วจะเห็นว่า function
explode มันก็คือการสร้าง list ของ (pos x y) char นั่นเองทดลอง run ดู
test> (explode 0 "hello")
([{:x 0, :y 0} \h] [{:x 1, :y 0} \e] [{:x 2, :y 0} \l] [{:x 3, :y 0} \l] [{:x 4, :y 0} \o])
กลับมาที่ line-explode, function ตัวสุดท้ายก็คือ
(reduce into (map ..))reduce รับ parameter เป็น function และ list
โดยมันจะเรียก function โดยมี parameter เป็นสมาชิกตัวที่ 1 และ 2 ของ list
จากนั้นก็จะเรียก function โดยมี parameter ตัวที่เป็นผลลัพท์ที่ได้จากครั้งก่อน กับ สมาชิกตัวที่ 3
ทำเช่นนี้ไปเรื่อยๆจนกว่าจะหมด
(reduce + [1 2 3 4 5])
=> 15
เขียนอีกอย่างก็คือ
(+ (+ (+ (+ 1 2) 3) 4) 5)
ส่วน
into นั้นทำงานแบบนี้(into [1] [2])
=> [1 2]
(into [1 2 3] [2])
=> [1 2 3 2]
(into [1] [1 2 3])
=>[1 1 2 3]
มันคือ operation ที่จับ array บวกกันนั่นเอง
สรุปแล้วจะเห็นว่าการ explode ก็คือการเปลี่ยน multi-line string ให้อยู่ในรูปของ [(pos x y) char] นั่นเอง
test> (line-explode "hello\nworld\n")
([{:x 4, :y 1} \d] [{:x 3, :y 1} \l] [{:x 2, :y 1} \r] [{:x 1, :y 1} \o] [{:x 0, :y 1} \w] [{:x 0, :y 0} \h] [{:x 1, :y 0} \e] [{:x 2, :y 0} \l] [{:x 3, :y 0} \l] [{:x 4, :y 0} \o])
Related link from Roti
Friday, November 21, 2008
เรียนรู้ clojure - data structure ตอน 2
ต่อจากเมื่อวาน
data structure ตัวถัดไปก็คือ map
ลองดูคำสั่งที่เขาใช้ (เขาใช้ map keyboard code เข้ากับ ทิศทาง)
เจ้าเครื่องหมาย { เป็น syntax อย่างย่อ
ถ้าจะสั่งแบบยาวหน่อย ก็ให้สั่งแบบนี้
เครื่องหมาย comma นั้นจะใส่หรือไม่ใส่ก็ได้
การ access ค่า สามารถทำได้โดยคำสั่ง
ถัดจาก map ก็คือ vector และ list
ทั้ง vector และ list จะใช้คำสั่งเหมือนกันอย่างกับแกะ ต่างกันตรง data structure ภายในที่เก็บ
เจ้า vector เวลาเรา add item เข้าไป, item นั้นจะไปต่อท้าย
ส่วน list นั้น ถ้าเรา add item เข้าไป, item จะไปอยู่ที่หัว
Note: จะเห็นเครื่องหมาย
เครื่องหมายนั้นจะบอก clojure ว่า (1 2 3) เป็น data นะ ไม่ต้องไป evaluate มัน
เวลาดูโปรแกรม clisp จะเห็นว่ามีเครื่องหมาย
แต่เจ้า clojure ที่ลอก syntax มา มีการดัดแปลง syntax ไปเล็กน้อย
โดยจะเห็นว่าเขาเอา vector มาใช้ define พวก parameter list, binding list
ซึ่งก็น่าจะทำให้ programmer recognise code ได้ไวขึ้น
data structure ตัวถัดไปก็คือ map
ลองดูคำสั่งที่เขาใช้ (เขาใช้ map keyboard code เข้ากับ ทิศทาง)
(def AsciiToDx {72 -1,
76 1,
75 0,
74 0})
เจ้าเครื่องหมาย { เป็น syntax อย่างย่อ
ถ้าจะสั่งแบบยาวหน่อย ก็ให้สั่งแบบนี้
(def AsciiToDx (hash-map 72 -1 76 1 75 0 74 0))
เครื่องหมาย comma นั้นจะใส่หรือไม่ใส่ก็ได้
(def AsciiToDx (hash-map 72 -1, 76 1, 75 0, 74 0))
การ access ค่า สามารถทำได้โดยคำสั่ง
getuser> (get AsciiToDx 72)
-1
ถัดจาก map ก็คือ vector และ list
ทั้ง vector และ list จะใช้คำสั่งเหมือนกันอย่างกับแกะ ต่างกันตรง data structure ภายในที่เก็บ
เจ้า vector เวลาเรา add item เข้าไป, item นั้นจะไปต่อท้าย
ส่วน list นั้น ถ้าเรา add item เข้าไป, item จะไปอยู่ที่หัว
user> (conj '(1 2 3) 4)
(4 1 2 3)
user> (conj [1 2 3] 4)
[1 2 3 4]
Note: จะเห็นเครื่องหมาย
' ที่หน้า list (1 2 3)เครื่องหมายนั้นจะบอก clojure ว่า (1 2 3) เป็น data นะ ไม่ต้องไป evaluate มัน
เวลาดูโปรแกรม clisp จะเห็นว่ามีเครื่องหมาย
() อยู่เต็มไปหมด (ชื่อภาษามันบอกอยู่แล้วว่ามันคือ list)แต่เจ้า clojure ที่ลอก syntax มา มีการดัดแปลง syntax ไปเล็กน้อย
โดยจะเห็นว่าเขาเอา vector มาใช้ define พวก parameter list, binding list
ซึ่งก็น่าจะทำให้ programmer recognise code ได้ไวขึ้น
Related link from Roti
Thursday, November 20, 2008
เรียนรู้ clojure - data structure
เมื่อวาน @somkiat post link http://blog.learnr.org/post/59883018/first-clojure-program ใน twiiter
ผมตามไปอ่านแล้ว รู้สึกถูกใจในขนาดและความยากที่ดูจะเหมาะแก่การเริ่มต้นเรียนรู้ Clojure
เริ่มกันที่ data structure ก่อน
ในโปรแกรมนี้เขาใช้ StructMaps ในการเก็บค่าต่างๆเช่น position ของ กำแพง,ผู้เล่น
โดย StructMaps นั้นสามารถสร้างได้โดยใช้คำสั่งู่แบบนี้
Note: เจ้าคำสั่ง defstruct จริงๆมันเป็นแค่ macro
สิ่งที่เกิดขึ้นจริงๆ ก็คือมันจะแปลงคำสั่ง
เวลาที่เราต้องการสร้าง data ก็ให้สั่งแบบนี้
ถ้าต้องการ get ค่า x ก็ให้สั่ง
เนื่องจาก Clojure พยายามเน้นที่ Parallel programming
ดังนั้น struct เมื่อสร้างขึ้นมาแล้ว ก็ไม่สามารถเปลี่ยนค่าภายในได้ (immutable)
ถ้าเราต้องการเปลี่ยนค่าภายใน ก็หมายถึงว่าเราต้องสร้าง data ใหม่ขึ้นมา
ดูตัวอย่างนี้
เจ้า StructMaps จริงๆแล้วก็คือ Map ที่ define keys ที่เป็นไปได้ไว้ (รวมทั้งลำดับด้วย)
เราสามารถใช้ คำสั่งต่างๆที่เกี่ยวกับ Map มาทำ operation บน StructMaps ได้หมด
เช่น
คำสั่งที่น่าสนใจ ก็คือ accessor
ที่ return function ที่ใช้ access value ของ StructMaps นั้นๆ
ในโปรแกรมจะเห็นตัวอย่างหนึ่งที่น่าสนใจก็คือ
เขาประกาศ struct ของ level ไว้ดังนี้
ที่น่าสนใจก็คือ ปกติถ้าเราต้องการสร้าง data ของ level เราก็ใช้คำสั่ง
แต่การใช้คำสั่งแบบนี้ จะทำให้สับสนภายหลังได้ง่าย ว่า ตัวแปร a,b,c,d หมายถึงอะไร
ดังนั้นวิธีการที่เหมาะก็คือ ใช้คำสั่ง struct-map ในการสร้าง data แทน
ผมตามไปอ่านแล้ว รู้สึกถูกใจในขนาดและความยากที่ดูจะเหมาะแก่การเริ่มต้นเรียนรู้ Clojure
เริ่มกันที่ data structure ก่อน
ในโปรแกรมนี้เขาใช้ StructMaps ในการเก็บค่าต่างๆเช่น position ของ กำแพง,ผู้เล่น
โดย StructMaps นั้นสามารถสร้างได้โดยใช้คำสั่งู่แบบนี้
(defstruct pos :x :y)
Note: เจ้าคำสั่ง defstruct จริงๆมันเป็นแค่ macro
สิ่งที่เกิดขึ้นจริงๆ ก็คือมันจะแปลงคำสั่ง
(defstruct pos :x :y) ให้เป็น (def pos (create-struct :x :y))เวลาที่เราต้องการสร้าง data ก็ให้สั่งแบบนี้
(struct pos 1 2)
ถ้าต้องการ get ค่า x ก็ให้สั่ง
(:x (struct pos 1 2))เนื่องจาก Clojure พยายามเน้นที่ Parallel programming
ดังนั้น struct เมื่อสร้างขึ้นมาแล้ว ก็ไม่สามารถเปลี่ยนค่าภายในได้ (immutable)
ถ้าเราต้องการเปลี่ยนค่าภายใน ก็หมายถึงว่าเราต้องสร้าง data ใหม่ขึ้นมา
ดูตัวอย่างนี้
user> (def mypos (struct pos 1 2)) ;; สร้างตัวแปร mypos ที่เก็บตำแหน่ง (1,2)
#=(var user/mypos)
user> (assoc mypos :x 10) ;; เปลี่ยนค่า x ให้เป็น 10
{:x 10, :y 2}
user> (:x mypos) ;; แสดงค่า x
1
user> (def mypos (assoc mypos :x 10)) ;; ถ้าต้องการเปลี่ยนก็หมายถึงว่าต้อง set mypos ให้ชี้ไปที่ StructMap ตัวใหม่ที่ return จาก assoc
#=(var user/mypos)
user> (:x mypos)
10
เจ้า StructMaps จริงๆแล้วก็คือ Map ที่ define keys ที่เป็นไปได้ไว้ (รวมทั้งลำดับด้วย)
เราสามารถใช้ คำสั่งต่างๆที่เกี่ยวกับ Map มาทำ operation บน StructMaps ได้หมด
เช่น
user> (vals mypos) ;; return values ของ mypos
(10 2)
user> (keys mypos) ;; return keys ของ mypos
(:x :y)
คำสั่งที่น่าสนใจ ก็คือ accessor
ที่ return function ที่ใช้ access value ของ StructMaps นั้นๆ
user> (def get-x (accessor pos :x))
#=(var user/get-x)
user> (get-x mypos)
10
ในโปรแกรมจะเห็นตัวอย่างหนึ่งที่น่าสนใจก็คือ
เขาประกาศ struct ของ level ไว้ดังนี้
(defstruct level
:player ; pos
:boxes ; set-of-pos
:goals ; set-of-pos
:walls ; set-of-pos
)
ที่น่าสนใจก็คือ ปกติถ้าเราต้องการสร้าง data ของ level เราก็ใช้คำสั่ง
(struct level a b c d) ได้แต่การใช้คำสั่งแบบนี้ จะทำให้สับสนภายหลังได้ง่าย ว่า ตัวแปร a,b,c,d หมายถึงอะไร
ดังนั้นวิธีการที่เหมาะก็คือ ใช้คำสั่ง struct-map ในการสร้าง data แทน
(struct-map level
:player (first (filter-level expl-level \@ \+))
:boxes (filter-level expl-level \o \*)
:goals (filter-level expl-level \. \* \+)
:walls (filter-level expl-level \# \#))))
Related link from Roti
Friday, November 14, 2008
fast-forward ใน git-merge
เห็นคำว่า Fast forward เวลาสั่ง git pull มานานแล้ว, มาอ่าน git-doc ก็เลยเข้าใจขึ้น
เวลาเราสั่ง git merge, การทำงานของมันสามารถแบ่งได้เป็น 3 ประเภท
เวลาเราสั่ง git merge, การทำงานของมันสามารถแบ่งได้เป็น 3 ประเภท
- ถ้า merged commit ที่เราดึงมา อยู่ใน Head(current tree ของเรา) ของเราแล้ว, ก็จะแสดงผลลัพท์ "Already up-to-date." แล้วก็จบการทำงาน
- ถ้า Head ของเราอยู่ใน commits ที่ดึงมา, case นี้มักเกิดจากคำสั่ง "git pull" เพื่อดึง code จากต้นน้ำมา update code(ที่ไม่มีการเปลี่ยนแปลง) ของเรา, สิ่งที่เกิดขึ้นก็คือ git จะ update HEAD ของเราให้ตรงตาม HEAD ของ merged commit (โดยไม่มีการสร้าง commit object ใหม่ขึ้นมา) มีศัพท์เฉพาะสำหรับกรณีนี้ว่า "Fast-forward"
- สุดท้ายเป็นกรณีที่เกิดการ merge จริงๆ นั่นคือ ตัว HEAD ของเรา independent กับ merged commit, ดังนั้นกรณนี้จะเกิดการ merge จริง และมีการสร้าง commmit object ใหม่ขึ้นมา
Related link from Roti
Thursday, November 13, 2008
config syntax ใน grails
ผมสงสัยเรื่อง configuration ใน grails มาได้พักใหญ่แล้ว
เพราะเห็น syntax มันแปลกประหลาดเหลือเกิน ลองดูตัวอย่างข้างล่างนี้
ทำไมบรรทัดที่สองต้องมี quote ครอบด้วยหล่ะ?
class ที่ทำหน้าที่อ่าน file Config.groovy ของ grails ก็คือ ConfigSlurper
โดยวิธีการใช้งานเจ้า ConfigSlurper ก็คือแบบนี้
สิ่งที่เจ้า ConfigSlurper return มาก็คือ Map ตัวหนึ่ง (มันคือ class ConfigObject ที่ extends จาก LinkedHashMap)
ที่นี้มาลองดู nature ของมันบ้าง
เริ่มจาก config ง่ายๆ บรรทัดเดียว
ผลลัพท์ที่ได้จากการ parse จะเป็น map หน้าตาแบบนี้
ที่นี้ถ้าลองเพิ่ม sub node เข้าไปใต้ subtopic แบบนี้
เมื่อลอง parse ดู แทนที่จะได้ผลลัพท์ เรากลับได้ exception แบบนี้แทน
ดูเหมือนว่าการทำงานภายในของมันก็คือ เมื่อมันต้องการ assign ค่า
ที่นี้ลอง config แบบนี้บ้าง
ผลลัพท์ที่ได้คือ
อ้าว แล้ว subofsubtopic1 ของเราหายไปไหนหล่ะ
กลายเป็นว่า subofsubtopic1 ของเราถูก เจ้า topic1.subtopic1 override ค่าไปเรียบร้อยแล้ว
ลองให้เหลือ บรรทัดเดียวแบบนี้ ดูบ้าง
ผลลัพท์ที่ได้ จะเป็นแบบนี้
สรุปได้ว่า เนื่องจาก ConfigSlurperใช้ nested map เป็น internal structure ในการเก็บผลลัพท์จากการ parse
ทำให้เกิดข้อจำกัดในการเก็บขึ้นมา ดังนั้นถ้าเราต้องการเก็บค่าแบบบ้างบนให้ได้ เราก็เลยต้อง hack มัน โดยการห่อค่าให้เป็น string แบบนี้แทน
ผลลัพท์ที่ได้จากการ map ก็จะเป็นแบบนี้
อืมม์ไม่สวยเป็นอย่างยิ่ง น่าจะมีคน refactor นะ
สรุปได้ว่า ถ้าเรานำไปใช้งาน configuration ของเรา (ถ้าใช้ grails ก็ต้องเจอแน่ๆ)
เราก็ควรจะออกแบบ tree ของเราดีๆ อย่าให้เกิดกรณีที่ parent node มีค่า value attach อยู่
(ให้มี valueได้เฉพาะ leaf node)
ไม่งั้นอาจจะปวดหัวว่า ทำไมค่า config ถึงหายไป หรือไม่ก็ ทำไมถึง get config ที่ต้องการไม่เจอ
เพราะเห็น syntax มันแปลกประหลาดเหลือเกิน ลองดูตัวอย่างข้างล่างนี้
log4j.appender.stdout = "org.apache.log4j.ConsoleAppender"
log4j.appender."stdout.layout"="org.apache.log4j.PatternLayout"
ทำไมบรรทัดที่สองต้องมี quote ครอบด้วยหล่ะ?
class ที่ทำหน้าที่อ่าน file Config.groovy ของ grails ก็คือ ConfigSlurper
โดยวิธีการใช้งานเจ้า ConfigSlurper ก็คือแบบนี้
def config = new ConfigSlurper().parse(new File('/tmp/x.groovy').toURL())
สิ่งที่เจ้า ConfigSlurper return มาก็คือ Map ตัวหนึ่ง (มันคือ class ConfigObject ที่ extends จาก LinkedHashMap)
ที่นี้มาลองดู nature ของมันบ้าง
เริ่มจาก config ง่ายๆ บรรทัดเดียว
topic1.subtopic1=1
ผลลัพท์ที่ได้จากการ parse จะเป็น map หน้าตาแบบนี้
["topic1":["subtopic1":1]]
ที่นี้ถ้าลองเพิ่ม sub node เข้าไปใต้ subtopic แบบนี้
topic1.subtopic1=1
topic1.subtopic1.subofsubtopic1="foo"
เมื่อลอง parse ดู แทนที่จะได้ผลลัพท์ เรากลับได้ exception แบบนี้แทน
groovy.lang.MissingPropertyException: No such property: subofsubtopic1 for class: java.lang.Integer
at script1226551599145.run(script1226551599145.groovy:2)
at Script9.run(Script9:1)
ดูเหมือนว่าการทำงานภายในของมันก็คือ เมื่อมันต้องการ assign ค่า
topic1.subtopic1.subofsubtopic1 มันจะไป get value โดยใช้ key topic1.subtopic1 จากนั้นก็พยายามจะ set property subofsubtopic1ลงใน value ที่ได้มาก ซึ่งไม่สำเร็จแน่ๆเพราะ value ที่ได้มันไม่ใช่ map อย่างที่ควรจะเป็นที่นี้ลอง config แบบนี้บ้าง
topic1.subtopic1.subofsubtopic1="foo"
topic1.subtopic1=1
ผลลัพท์ที่ได้คือ
["topic1":["subtopic1":1]]
อ้าว แล้ว subofsubtopic1 ของเราหายไปไหนหล่ะ
กลายเป็นว่า subofsubtopic1 ของเราถูก เจ้า topic1.subtopic1 override ค่าไปเรียบร้อยแล้ว
ลองให้เหลือ บรรทัดเดียวแบบนี้ ดูบ้าง
topic1.subtopic1.subofsubtopic1="foo"
ผลลัพท์ที่ได้ จะเป็นแบบนี้
["topic1":["subtopic1":["subofsubtopic1":"foo"]]]
สรุปได้ว่า เนื่องจาก ConfigSlurperใช้ nested map เป็น internal structure ในการเก็บผลลัพท์จากการ parse
ทำให้เกิดข้อจำกัดในการเก็บขึ้นมา ดังนั้นถ้าเราต้องการเก็บค่าแบบบ้างบนให้ได้ เราก็เลยต้อง hack มัน โดยการห่อค่าให้เป็น string แบบนี้แทน
topic1.subtopic1=1
topic1."subtopic1.subofsubtopic1"="foo"
ผลลัพท์ที่ได้จากการ map ก็จะเป็นแบบนี้
["topic1":["subtopic1":1, "subtopic1.subofsubtopic1":"foo"]]
อืมม์ไม่สวยเป็นอย่างยิ่ง น่าจะมีคน refactor นะ
สรุปได้ว่า ถ้าเรานำไปใช้งาน configuration ของเรา (ถ้าใช้ grails ก็ต้องเจอแน่ๆ)
เราก็ควรจะออกแบบ tree ของเราดีๆ อย่าให้เกิดกรณีที่ parent node มีค่า value attach อยู่
(ให้มี valueได้เฉพาะ leaf node)
ไม่งั้นอาจจะปวดหัวว่า ทำไมค่า config ถึงหายไป หรือไม่ก็ ทำไมถึง get config ที่ต้องการไม่เจอ
Related link from Roti
Tuesday, October 28, 2008
Change blindness
ในปี 1998 Simons, D., & Levin, D. ได้เขียน paper ที่น่าสนใจ ชื่อว่า
Failure to Detect Changes to People During a Real-World Interaction
เขาทดลองให้ หน้าม้าปลอมตัวเป็นนักท่องเที่ยว จากนั้นก็ให้หน้าม้าทำทีกางแผนที่เข้าไปสอบถามเส้นทาง กับ เป้าหมาย
จังหวะที่กำลังสอบถามนั้น ก็ให้หน้าม้าอีกสองคน ถือประตู(กำลังขนประตูไปที่ไหนสักแห่ง) เดินแทรกกลางเข้ามาระหว่าง หน้าม้านักท่องเที่ยว กับเป้าหมาย
จังหวะที่ประตูกำลังบังเป้าหมายอยู่นั้น ก็ถือโอกาสสลับเปลี่ยนตัวหน้าม้าที่ทำตัวเป็นนักท่องเที่ยว
คำถามของเขาก็คือ เป้าหมายจะรู้หรือไม่ว่า มีการสลับตัวเกิดขึ้น
ครั้งที่ 1 เขาทดลอง 15 ครั้ง 7 ใน 15 บอกว่าสังเกตเห็นการเปลี่ยนแปลง ที่น่าสนใจก็คือ 7 คน นั้นอยู่ในช่วงอายุ 20-30 ปี ซึ่งเป็นช่วงอายุเดียวกับหน้าม้า
ส่วนเป้าหมายที่ไม่เห็นการเปลี่ยนแปลง จะอยู่ในช่วงอายุ 30-60 ปี
เขาตั้งข้อสงสัยว่า social group มีส่วนเกี่ยวข้องด้วยหรือไม่? (สมมติฐานมีอยู่ว่า เรา treat คนไม่เท่าเทียมกัน โดยให้ความสำคัญกับกลุ่มที่เป็นพวกเดียวกับเรามากกว่า) เขาก็เลยทำการทดลองใหม่อีกครั้ง คราวนี้เปลี่ยนรูปลักษณ์หน้าม้า โดยแปลงร่างเป็นช่างก่อสร้าง
(ที่พิเศษว่าครั้งแรก ก็คือ หน้าม้าใส่เสื้อคนละสีเลย เมื่อเทียบกับครั้งแรกที่ยังแต่งตัวเหมือนๆกันอยู่)
จากการทดลอง 12 ครั้ง กับเป้าหมายที่อายุ 20-30 ปี พบว่า มีแค่ 4 คนเท่านั้นที่สังเกตุเห็นการเปลี่ยนแปลง
? blindness นั้นเกิดจากอะไร, เป็นข้อจำกัดทางกายภาพของเรา
หรือเกิดจากการที่เราหมกมุ่นกับความคิดที่อยู่ใน "หัว" ของเรามากเกินไป
ตามไปดูรูปและรายละเอียดได้ที่นี่
Failure to Detect Changes to People During a Real-World Interaction
เขาทดลองให้ หน้าม้าปลอมตัวเป็นนักท่องเที่ยว จากนั้นก็ให้หน้าม้าทำทีกางแผนที่เข้าไปสอบถามเส้นทาง กับ เป้าหมาย
จังหวะที่กำลังสอบถามนั้น ก็ให้หน้าม้าอีกสองคน ถือประตู(กำลังขนประตูไปที่ไหนสักแห่ง) เดินแทรกกลางเข้ามาระหว่าง หน้าม้านักท่องเที่ยว กับเป้าหมาย
จังหวะที่ประตูกำลังบังเป้าหมายอยู่นั้น ก็ถือโอกาสสลับเปลี่ยนตัวหน้าม้าที่ทำตัวเป็นนักท่องเที่ยว
คำถามของเขาก็คือ เป้าหมายจะรู้หรือไม่ว่า มีการสลับตัวเกิดขึ้น
ครั้งที่ 1 เขาทดลอง 15 ครั้ง 7 ใน 15 บอกว่าสังเกตเห็นการเปลี่ยนแปลง ที่น่าสนใจก็คือ 7 คน นั้นอยู่ในช่วงอายุ 20-30 ปี ซึ่งเป็นช่วงอายุเดียวกับหน้าม้า
ส่วนเป้าหมายที่ไม่เห็นการเปลี่ยนแปลง จะอยู่ในช่วงอายุ 30-60 ปี
เขาตั้งข้อสงสัยว่า social group มีส่วนเกี่ยวข้องด้วยหรือไม่? (สมมติฐานมีอยู่ว่า เรา treat คนไม่เท่าเทียมกัน โดยให้ความสำคัญกับกลุ่มที่เป็นพวกเดียวกับเรามากกว่า) เขาก็เลยทำการทดลองใหม่อีกครั้ง คราวนี้เปลี่ยนรูปลักษณ์หน้าม้า โดยแปลงร่างเป็นช่างก่อสร้าง
(ที่พิเศษว่าครั้งแรก ก็คือ หน้าม้าใส่เสื้อคนละสีเลย เมื่อเทียบกับครั้งแรกที่ยังแต่งตัวเหมือนๆกันอยู่)
จากการทดลอง 12 ครั้ง กับเป้าหมายที่อายุ 20-30 ปี พบว่า มีแค่ 4 คนเท่านั้นที่สังเกตุเห็นการเปลี่ยนแปลง
? blindness นั้นเกิดจากอะไร, เป็นข้อจำกัดทางกายภาพของเรา
หรือเกิดจากการที่เราหมกมุ่นกับความคิดที่อยู่ใน "หัว" ของเรามากเกินไป
ตามไปดูรูปและรายละเอียดได้ที่นี่
Related link from Roti
Friday, October 17, 2008
Local Loop Expression ภาค 2
วันนี้เห็น code การบ้าน haskell ของ Porges
ตรงส่วนของการวน loop รับ entry ของ user
โดย user ต้องเลือก choice ว่าอยากให้โปรแกรมเป็น c(client) หรือ s(server)
โดย code มีหน้าตาแบบนี้
ประเด็นที่ผมสนใจ ก็คือ การวนลูป รับค่าจาก user และตรวจสอบว่าเป็นค่าที่ถูกต้องไหม
ตรงนี้เขา define function ที่ชื่อ untilM เข้ามาช่วย
หน้าตาของ untilM
จะเห็นว่า untilM รับ arguments 2 ตัวคือ p(predicate) กับ x
โดยมันจะทำ x ก่อน
ผลลัพท์ที่ได้จะถูก test ด้วย p
ถ้าผ่าน ก็จะ return กลับมา ถ้าไม่ผ่านก็ recursive รับค่าต่อไป
เห็นแล้วก็นึกถึง Local loop expression ที่เคยเขียนถึง
ก็เลยลองจับ untilM มาเขียนใหม่ด้วย fix ได้หน้าตาแบบนี้ออกมา
ดูแล้วก็ยังไม่สวยถูกใจเท่าไรนัก
ตรงส่วนของการวน loop รับ entry ของ user
โดย user ต้องเลือก choice ว่าอยากให้โปรแกรมเป็น c(client) หรือ s(server)
โดย code มีหน้าตาแบบนี้
main = withSocketsDo $ do -- enable sockets under windows
putStrLn "Welcome to One-Way Chat version 1.0"
...
input <- untilM -- get input of 'c' or 's'
(\x -> (not $ null x) && toLower (head x) `elem` "cs")
(putStr "Client or server? " >> getLine)
...
ประเด็นที่ผมสนใจ ก็คือ การวนลูป รับค่าจาก user และตรวจสอบว่าเป็นค่าที่ถูกต้องไหม
ตรงนี้เขา define function ที่ชื่อ untilM เข้ามาช่วย
หน้าตาของ untilM
-- monadic `until`
untilM p x = x >>= (\y -> if p y then return y else untilM p x)
จะเห็นว่า untilM รับ arguments 2 ตัวคือ p(predicate) กับ x
โดยมันจะทำ x ก่อน
ผลลัพท์ที่ได้จะถูก test ด้วย p
ถ้าผ่าน ก็จะ return กลับมา ถ้าไม่ผ่านก็ recursive รับค่าต่อไป
เห็นแล้วก็นึกถึง Local loop expression ที่เคยเขียนถึง
ก็เลยลองจับ untilM มาเขียนใหม่ด้วย fix ได้หน้าตาแบบนี้ออกมา
import Control.Monad.Fix
main = do ...
...
input <- fix (\loop ->
do putStr "Client or server? "
l <- getLine
if head(l) `elem` "cs" then return l else loop)
...
ดูแล้วก็ยังไม่สวยถูกใจเท่าไรนัก
Related link from Roti
Saturday, October 04, 2008
thunks
พึ่งได้เห็นคำว่า
ซึ่งเขาบอกว่าการเขียน JQuery นั้น, มันบังคับให้ใช้ form แบบ thunks เยอะมาก
และเขาก็ยกตัวอย่าง code มาให้ดูด้วย
ใน code ข้างบนบั้น, thunks ก็คือ function ที่ไม่มี parameter
และวัตถุประสงค์การใช้มัน ก็คือ delay การทำงานของ code ในส่วนที่เราต้องการส่งไปเป็น argument
ต้องท้าวความนิดหนึ่ง สำหรับคนที่ตามไม่ทัน
ใน programming language ส่วนใหญ่
argument ที่เราส่งไปให้ function หรือ procedure
จะถูก evulate ก่อนที่จะถูกส่งเข้าไปใน function
ยกตัวอย่าง syntax แบบนี้
ในหลายๆภาษาเราไม่สามารถสร้าง function ให้เรียนแบบ syntax ข้างบนได้
เพราะถ้าเราลองเขียนแบบข้างล่างนี้ดู เราจะพบว่า t กับ f จะถูก evaluate ก่อนที่จะ check if เสมอ
สำหรับผมหลังจากนั่งงงดู code สักพักแล้วก็ร้องอ๋อ ว่า มันคาบเกี่ยวกับเรื่องของ higher order function
แล้วก็ closure ด้วย (คิดว่า thunk จริงๆใน lisp ซึ่งเป็นต้นกำเนิดของคำนี้ น่าจะมีความหมายมากกว่านี้)
อ่านรายละเอียดเพิ่มเติมใน wikipedia-thunk
thunks จาก blog ของ Phil Windleyซึ่งเขาบอกว่าการเขียน JQuery นั้น, มันบังคับให้ใช้ form แบบ thunks เยอะมาก
และเขาก็ยกตัวอย่าง code มาให้ดูด้วย
$(document).ready(function() {
$("#orderedlist li:last").hover(function() {
$(this).addClass("green");
},function(){
$(this).removeClass("green");
});
});
ใน code ข้างบนบั้น, thunks ก็คือ function ที่ไม่มี parameter
และวัตถุประสงค์การใช้มัน ก็คือ delay การทำงานของ code ในส่วนที่เราต้องการส่งไปเป็น argument
ต้องท้าวความนิดหนึ่ง สำหรับคนที่ตามไม่ทัน
ใน programming language ส่วนใหญ่
argument ที่เราส่งไปให้ function หรือ procedure
จะถูก evulate ก่อนที่จะถูกส่งเข้าไปใน function
ยกตัวอย่าง syntax แบบนี้
expr ? Texpr: Fexpr
ในหลายๆภาษาเราไม่สามารถสร้าง function ให้เรียนแบบ syntax ข้างบนได้
เพราะถ้าเราลองเขียนแบบข้างล่างนี้ดู เราจะพบว่า t กับ f จะถูก evaluate ก่อนที่จะ check if เสมอ
int ifexpr( int x, int t, int f )
{
if( x ) return t;
return f;
}
สำหรับผมหลังจากนั่งงงดู code สักพักแล้วก็ร้องอ๋อ ว่า มันคาบเกี่ยวกับเรื่องของ higher order function
แล้วก็ closure ด้วย (คิดว่า thunk จริงๆใน lisp ซึ่งเป็นต้นกำเนิดของคำนี้ น่าจะมีความหมายมากกว่านี้)
อ่านรายละเอียดเพิ่มเติมใน wikipedia-thunk
Related link from Roti
Monday, September 22, 2008
Local Loop Expression
เคยเขียนถึง Y combinator ไปที
ตอนนั้นก็ไม่เคยคิดว่า มันจะมีตัวอย่างการใช้งานในชีวิตจริง
วันนี้ได้เห็นตัวอย่างการนำไปใช้ ที่น่าสนใจ
โดยเขาเอามันมาทำ local loop expression
ในตัวอย่างข้างบน forkIO คือการแตก thread ออกไปทำงาน,
fix คือ function ที่ทำให้เกิด magic
โดยมันทำให้เราทำ recursive แบบไม่ต้องประกาศชื่อ function ได้
(ในตัวอย่าง loop ก็คือ function ที่ pass เข้ามา, ถ้าเราอยากให้มัน recursive ทำ ก็ให้เรียกมันซ้ำ)
ใน xmonad ที่เป็น window manager ที่เขียนด้วย haskell ก็มีใช้แบบนี้
โดยการทำงานก็คือการวน loop ตรวจสอบ windows event
เจ้า function fix มันอยู่ใน module Control.Monad.Fix
ซึ่งเกิดจาก paper นี้
ใครธาตุไฟแข็งแรงก็เข้าไปอ่านได้ครับ (ผมเปิดดูแล้วก็ปิดทันที)
ตอนนั้นก็ไม่เคยคิดว่า มันจะมีตัวอย่างการใช้งานในชีวิตจริง
วันนี้ได้เห็นตัวอย่างการนำไปใช้ ที่น่าสนใจ
โดยเขาเอามันมาทำ local loop expression
reader <- forkIO $ fix $ \loop -> do
(nr', line) <- readChan chan'
when (nr /= nr') $ hPutStrLn hdl line
loop
ในตัวอย่างข้างบน forkIO คือการแตก thread ออกไปทำงาน,
fix คือ function ที่ทำให้เกิด magic
โดยมันทำให้เราทำ recursive แบบไม่ต้องประกาศชื่อ function ได้
(ในตัวอย่าง loop ก็คือ function ที่ pass เข้ามา, ถ้าเราอยากให้มัน recursive ทำ ก็ให้เรียกมันซ้ำ)
ใน xmonad ที่เป็น window manager ที่เขียนด้วย haskell ก็มีใช้แบบนี้
โดยการทำงานก็คือการวน loop ตรวจสอบ windows event
f = fix $ \again -> do
more <- checkMaskEvent d enterWindowMask ev
when more again
เจ้า function fix มันอยู่ใน module Control.Monad.Fix
ซึ่งเกิดจาก paper นี้
ใครธาตุไฟแข็งแรงก็เข้าไปอ่านได้ครับ (ผมเปิดดูแล้วก็ปิดทันที)
Related link from Roti
Friday, September 12, 2008
เขียน Rome 's plugin
ถ้าจะต้องเขียนโปรแกรม parse feed, เราสามารถเลือกวิธีการได้หลายวิธี
แบบที่ง่ายที่สุดก็คือ ใช้พวก xml parser library ซึ่งมีอยู่มากมาย
เรื่องกวนใจที่ตามมาก็คือ feed มันมี format หลักๆอยู่ 2 แบบ คือ rss และ atom
โปรแกรม parser เราก็เลยฉลาดขึ้นมาอีกนิดหนึ่ง (จะเขียนโดยใช้ if หรือแยก function หรือแนว OOP ก็ว่าไป)
ในส่วนตัวผม ผมเลือกใช้ Rome (มันเป็น Java !!!)
ซึ่งเป็น api ในการ parse feed
โดยมันจะซ่อนความแตกต่างของโครงสร้างระหว่าง RSS และ ATOM ไว้จากเรา
ปัญหาที่เจอก็คือ กรณีที่เราไปดึง feed จาก FeedBurner
มันจะมี extension element จำนวนหนึ่งที่ Rome ไม่รู้จัก (ทำให้ไม่มี method ให้ get ค่าเหล่านั้น)
ยกตัวอย่าง Feed ของ Feedburner มันจะมีหน้าตาแบบนี้
สิ่งที่เราต้องการก็คือ
แต่โชคดีที่คนออกแบบ Rome เขามองการณ์ไกล เขาก็เลยเตรียมช่อง plugin ให้เราไว้แล้ว
วิธีการก็คือ เราต้องสร้าง (High Level) Parser ของเราขึ้นมาตัวหนึ่ง
และทำการ register มันเข้ากับ Rome
เจ้า Parser ตัวนี้ จะถูกเรียกใช้หลังจากที่ Rome สร้าง DOM structure ขึ้นมาแล้ว
หน้าที่ของ parser ก็คือ return Object ที่ wrap ค่าที่เราต้องการไว้
ตัวอย่าง code
ในฝั่งคนใช้งาน ถ้าเขียนเป็น groovy ก็เขียนง่ายๆแบบนี้
แบบที่ง่ายที่สุดก็คือ ใช้พวก xml parser library ซึ่งมีอยู่มากมาย
เรื่องกวนใจที่ตามมาก็คือ feed มันมี format หลักๆอยู่ 2 แบบ คือ rss และ atom
โปรแกรม parser เราก็เลยฉลาดขึ้นมาอีกนิดหนึ่ง (จะเขียนโดยใช้ if หรือแยก function หรือแนว OOP ก็ว่าไป)
ในส่วนตัวผม ผมเลือกใช้ Rome (มันเป็น Java !!!)
ซึ่งเป็น api ในการ parse feed
โดยมันจะซ่อนความแตกต่างของโครงสร้างระหว่าง RSS และ ATOM ไว้จากเรา
ปัญหาที่เจอก็คือ กรณีที่เราไปดึง feed จาก FeedBurner
มันจะมี extension element จำนวนหนึ่งที่ Rome ไม่รู้จัก (ทำให้ไม่มี method ให้ get ค่าเหล่านั้น)
ยกตัวอย่าง Feed ของ Feedburner มันจะมีหน้าตาแบบนี้
<feed xmlns:feedburner="http://rssnamespace.org/feedburner/ext/1.0">
...
<entry>
<title>xxx</title>
<content>yyyy<content>
<author>bact'</author>
<link href="http://feeds.feedburner.com/~r/bact/~3/326895937/hauntedness-management.html"/>
<feedburner:origLink href="http://bact.blogspot.com/2008/07/hauntedness-management.html"/>
</entry>
...
</feed>
สิ่งที่เราต้องการก็คือ
origLink ซึ่ง ROME ไม่มี api ให้ใช้แต่โชคดีที่คนออกแบบ Rome เขามองการณ์ไกล เขาก็เลยเตรียมช่อง plugin ให้เราไว้แล้ว
วิธีการก็คือ เราต้องสร้าง (High Level) Parser ของเราขึ้นมาตัวหนึ่ง
และทำการ register มันเข้ากับ Rome
เจ้า Parser ตัวนี้ จะถูกเรียกใช้หลังจากที่ Rome สร้าง DOM structure ขึ้นมาแล้ว
หน้าที่ของ parser ก็คือ return Object ที่ wrap ค่าที่เราต้องการไว้
ตัวอย่าง code
public class Parser implements ModuleParser {
public String getNamespaceUri() {
return FeedburnerModule.FEEDBURNER_URI;
}
public Module parse(Element element) {
Element origLink = element.getChild("origLink", FeedburnerModule.FEEDBURNER_NS);
if (origLink != null) {
FeedburnerModuleImpl impl = new FeedburnerModuleImpl(FeedburnerModule.class, FeedburnerModule.FEEDBURNER_URI);
impl.setOrigLink(origLink.getTextTrim());
return impl;
}
return null;
}
}
ในฝั่งคนใช้งาน ถ้าเขียนเป็น groovy ก็เขียนง่ายๆแบบนี้
def entry0 = feed.entries[0]
def module = entry0.getModule('http://rssnamespace.org/feedburner/ext/1.0')
assertEquals 'http://bact.blogspot.com/2008/07/hauntedness-management.html', module.origLink
Related link from Roti
Sunday, August 31, 2008
barcampbangkok2
ในงานผมได้พูดเรื่อง "25 วัน เชียงใหม่-กรุงเทพฯ โดยเรือแคนนู"
แต่ตอน present ผมเปิด google map ไม่ได้
เลยขอลง map ให้ดูในนี้แล้วกัน
View Larger Map
ส่วนรูปดูได้ที่นี่
เรื่องประทับใจในงาน barcampbangkok2 ของผม
ข้อสังเกต
แต่ตอน present ผมเปิด google map ไม่ได้
เลยขอลง map ให้ดูในนี้แล้วกัน
View Larger Map
ส่วนรูปดูได้ที่นี่
 |
| 25days |
เรื่องประทับใจในงาน barcampbangkok2 ของผม
- เนื้อหาที่ประทับใจมากที่สุด เรื่อง Riding on Fans’ Energy: Touhou, Fan Culture, and Grassroot Entertainment ของอาจารย์โป้ง ที่พูดเกี่ยวกับปรากฎการณ์ของเกมส์ Touhou
เกมส์ที่สร้างโดยคนคนเดียว แต่สามารถจัด event ที่บรรดาแฟนๆ 47,000 คนมาร่วมงานได้
ใครสนใจตามไปอ่านบทความของอาจารย์โป้งได้ที่นี่ Link
ไม่ใช่แต่เนื้อหาเท่านั้นที่น่าสนใจ ประเด็นที่น่าสนใจอีกอย่างก็คือ
ตอนที่อาจารย์โป้งพูดนั้น เวลาดันหมดเสียก่อน
แต่ด้วย spirit ของ barcamp, คนฟังก็เลยรวมตัวกันเปิดห้องขึ้นใหม่อีกห้องหนึ่ง เพื่อฟังต่อให้จบ
ข้อสังเกต
- จำนวนห้องที่มากถึง 8 ห้อง ทำให้เกิด paradox of choice เล็กๆขึ้นมา
- 2 วันนี่เหนื่อยไปหน่อย, ดูเหมือน climax จะไปอยู่ที่ beercamp ทำให้อีกวันดูเงียบๆไปหน่อย
- ขาดบริเวณพักผ่อนกลาง ที่เปิดโอกาสให้นั่งเล่น และ present งานสำหรับคนที่ไม่ได้ถูกเลือกหัวข้อ
Related link from Roti
Tuesday, August 26, 2008
rabbiter
@sugree tweet ถามถึง Rabbiter, ด้วยความที่ไม่รู้ว่ามันคืออะไร ก็เลยต้องไปหาข้อมูลมาอ่านก่อน
เป้าหมายของเจ้า rabbiter ก็คือ
เจ้า rabbitter จริงๆแล้วก็คือ module extension ของ ejabberd โดยมันจะประพฤติตนเป็น bot คอยโต้ตอบกับเรา
หน้าที่ของมันก็คือการ relay message ของคนอื่นๆที่เราสนใจ (follow) มาให้เรา หรือ ส่งต่อข้อความของเรา ไปให้กับคนอื่นที่สนใจติดตามเรา (follower)
โดยการ relay นี้สามารถทำข้ามวง ejabberd server ได้
ในแง่ architecture ประเด็นที่น่าสนใจก็คือ มันใช้ messageing queue (rabbitmq) เข้ามา handle publisher-subscriber model.
อ่านเอกสารอธิบายอย่างละเอียดได้ที่นี่
https://dev.rabbitmq.com/wiki/RabbiterFederation
Note: ตอนทดสอบต้องระวังประเด็นที่ IM client แอบแก้ message ของเรา เช่น pidgin บน linux, ที่เวลาเราสั่ง
เป้าหมายของเจ้า rabbiter ก็คือ
using XMPP to build a decentralized microblogging platform (think Twitter busted apart to run as a distributed network of microblogging providers)
หลักการทำงาน
เจ้า rabbitter จริงๆแล้วก็คือ module extension ของ ejabberd โดยมันจะประพฤติตนเป็น bot คอยโต้ตอบกับเรา
หน้าที่ของมันก็คือการ relay message ของคนอื่นๆที่เราสนใจ (follow) มาให้เรา หรือ ส่งต่อข้อความของเรา ไปให้กับคนอื่นที่สนใจติดตามเรา (follower)
โดยการ relay นี้สามารถทำข้ามวง ejabberd server ได้
ในแง่ architecture ประเด็นที่น่าสนใจก็คือ มันใช้ messageing queue (rabbitmq) เข้ามา handle publisher-subscriber model.
อ่านเอกสารอธิบายอย่างละเอียดได้ที่นี่
https://dev.rabbitmq.com/wiki/RabbiterFederation
วิธีการ install
- ติดตั้ง erlang, เนื่องจาก erlang compile ได้ง่ายๆ ดังนั้นใช้วิธี download source code มา compile เองดีกว่า
version ที่ผมใช้ก็คือ r12-b3 - ติดตั้ง rabbitemq-server
ตัวนี้ให้ download source version 1.4.0 มา เวลา compile ก็แค่สั่ง make เป็นอันเสร็จพิธี - ทำให้ erlang มองเห็น rabbitmq-server module
ถ้าเราติดตั้ง erlang ด้วยการ compile code เอง, modules path ของ erlang จะอยู่ที่ /usr/local/lib/erlang/lib
โดยมีหน้าตาประมาณนี้
pphetra@[/usr/local/lib/erlang/lib]
$ ls
appmon-2.1.9 dialyzer-1.8.1 mnesia-4.4.3 ssl-3.9
asn1-1.5.2 docbuilder-0.9.8.4 observer-0.9.7.4 stdlib-1.15.3
common_test-1.3.2 edoc-0.7.6 orber-3.6.9 syntax_tools-1.5.5
...
ให้ทำ symbolic link กับ directory rabbitmq-server-1.4.0
Note: ตรงนี้ให้ระวังชื่อด้วย เพราะ code ของ rabbiter มันต้องการให้เป็นชื่อ rabbitmq_server เป๊ะๆ
$ ls -l rab*
lrwxr-xr-x 1 root pphetra 40 Aug 27 13:05 rabbitmq_server -> /Users/pphetra/dev/rabbitmq-server-1.4.0 - ขั้นถัดไปก็ clone เจ้า rabbiter จาก github
Note: ใครที่สั่ง clone แล้วเกิด error timeout ให้ลองเปลี่ยน url จาก git://github.com/tonyg/rabbiter.git
เป็น http://github.com/tonyg/rabbiter.git
เมื่อได้มาแล้ว ก็ทิ้งไว้ก่อน เดี๋ยวเราจะไปฝาก compile กับ ejabberd - ติดตั้ง ejabberd, ตัวนี้ให้ใช้ version 2.0.1
ก่อน compile ก็ให้ไปแอบทำ symbolic link เจ้า file mod_rabbiter.erl เข้ามาใน directory ejabberd-2.0.1/src เสียก่อน
(หรือจะเล่นลูกทุ่ง copy เอาดื้อๆ ก็ไม่ผิด) - config ejabberd ให้รู้จัก rabbiter
โดย edit /etc/ejabberd/ejabberd.cfg
เพิ่ม บรรทัดนี้ลงไป
{modules,
[
{mod_adhoc, []},
{mod_announce, [{access, announce}]}, % recommends mod_adhoc
{mod_caps, []},
...
{mod_rabbiter, []},
...
การทดสอบ
- สั่ง start ejabberd ด้วยคำสั่ง
/sbin/ejabberdctl start
ตรวจสอบว่า start สำเร็จหรือไม่ ด้วยคำสั่ง/sbin/ejabberdctl status
$ ./ejabberdctl status
Node ejabberd@localhost is started. Status: started
ejabberd is running - add user
$ ./ejabberdctl register pphetra localhost mypassword
$ ./ejabberdclt register sugree localhost anypassword - ทดลองใช้ IM ต่อเข้ามา โดยระบุตัวตนเป็น pphetra
จากนั้นก็ add contact rabbiter@rabbiter.localhost
ลองสั่ง*helpก็จะได้ message แบบนี้
To give me a command, choose one from the list below. Make sure you prefix it with '*', otherwise I'll interpret it as something you want to send to your group of followers. You can say '*help (command)' to get details on a command you're interested in. If you want to actually say 'help', rather than asking for help, type '*say help' instead.
["*help","*follow","*unfollow","*following","*followers",
"*invite"]
ลองสั่ง*follow sugree@localhostก็จะได้รับ message แบบนี้
You are now following sugree@localhost.
Note: user sugree ต้องเคย logon ก่อนด้วย IM client ไม่งั้น จะได้ error เป็นแบบนี้
I don't know that person. Perhaps you could invite them to get in touch?
Note: ตอนทดสอบต้องระวังประเด็นที่ IM client แอบแก้ message ของเรา เช่น pidgin บน linux, ที่เวลาเราสั่ง
*follow x@y มันจะแอบเปลี่ยนเป็น *follow x@y <mailto:x@y> ซึ่งส่งผลให้ rabbiter ไม่รู้จักคำสั่งนี้
Related link from Roti
Friday, August 22, 2008
Specifying revisions
หลายคนคงเคยผ่านตากับการอ้างถึง parent ของ branch แบบนี้ (เครื่องหมาย ^)
ถ้าไปเปิด man page ของ git-rev-parse จะพบ diagram ที่ช่วยให้เราเข้าใจถึงการใช้
Note: tree มันกลับหัว, A คือ ยอดบนสุดของ ที่เกิดจากการ merge B กับ C
git checkout HEAD^^
ถ้าไปเปิด man page ของ git-rev-parse จะพบ diagram ที่ช่วยให้เราเข้าใจถึงการใช้
^
Here is an illustration, by Jon Loeliger. Both node B and C are a
commit parents of commit node A. Parent commits are ordered
left-to-right.
G H I J
\ / \ /
D E F
\ | / \
\ | / |
\|/ |
B C
\ /
\ /
A
A = = A^0
B = A^ = A^1 = A~1
C = A^2 = A^2
D = A^^ = A^1^1 = A~2
E = B^2 = A^^2
F = B^3 = A^^3
G = A^^^ = A^1^1^1 = A~3
H = D^2 = B^^2 = A^^^2 = A~2^2
I = F^ = B^3^ = A^^3^
J = F^2 = B^3^2 = A^^3^2
Note: tree มันกลับหัว, A คือ ยอดบนสุดของ ที่เกิดจากการ merge B กับ C
Related link from Roti
Friday, August 15, 2008
Do anything at barcamp bangkok 2
keyword ของ barcamp ก็คือ "เนื้อหา เกิดจาก ผู้เข้าร่วม"
คนพูดไม่จำเป็นต้องเป็น expert ในสิ่งที่พูดหรอก แค่มีประสบการณ์ดีๆที่อยากแบ่งปัน ก็เพียงพอแล้ว
มาร่วมกันสร้างอนาคตใหม่ให้กับวงการ IT เมืองไทย ด้วยการเปลี่ยนจาก ผู้รับ(passive) เป็น ผู้ให้(active) กันเถอะ
credits
เด็กตีลังกา - เด็กชายปัณณ์
เด็กห้อยหัว - เด็กชายปุณณ์
เด็กที่คนหัวโล้นอุ้ม - เด็กหญิงนมนต์ (สะกดถูกหรือเปล่าเนี่ย)
ผู้ชายกางเกงลาย - ผมเอง
ผู้ชายหัวโล้น - roofimon
คนถ่าย - keng
สถานที่ - opendream.org
คนพูดไม่จำเป็นต้องเป็น expert ในสิ่งที่พูดหรอก แค่มีประสบการณ์ดีๆที่อยากแบ่งปัน ก็เพียงพอแล้ว
มาร่วมกันสร้างอนาคตใหม่ให้กับวงการ IT เมืองไทย ด้วยการเปลี่ยนจาก ผู้รับ(passive) เป็น ผู้ให้(active) กันเถอะ
credits
เด็กตีลังกา - เด็กชายปัณณ์
เด็กห้อยหัว - เด็กชายปุณณ์
เด็กที่คนหัวโล้นอุ้ม - เด็กหญิงนมนต์ (สะกดถูกหรือเปล่าเนี่ย)
ผู้ชายกางเกงลาย - ผมเอง
ผู้ชายหัวโล้น - roofimon
คนถ่าย - keng
สถานที่ - opendream.org
Related link from Roti
Monday, August 04, 2008
code ของ grails 's plugin
คราวก่อนที่เจอปัญหา xml-rpc บน grails, ผมได้นั่งแกะโครงสร้าง plugins ของ grails ไปแวบหนึ่ง
รู้สึกติดใจว่า ถ้ามีเวลาต้องมานั่งแกะให้เป็นเรื่องเป็นราว
วันนี้ได้ที ใน mailing list ของ th-grails-user มีปัญหาซึ่งพาดพิงถึง mail-plugin
ก็เลยจัดการ install แล้วก็นั่งแกะ code ว่ามันทำอะไรบ้าง
function หลักๆที่ mail plugin ทำก็คือ
code ในส่วนของ function แรกที่น่าสนใจ ก็คือการ define bean 'mailSender'
ลองดู code ที่มันใช้
method นี้จะถูกเรียกใช้ในช่วง startup ของ grails
ซึ่งข้างในจะเห็นว่ามันใช้ DSL ในการ config spring
code ข้างบน ถ้าเขียนในแบบดั้งเดิมของ spring ก็จะออกมาทำนองนี้
ข้อได้เปรียบที่เห็นได้ชัด สำหรับการใช้ DSL ในการ config spring ก็คือ
เราสามารถใส่ logic ลงไปได้ (เพราะมันเป็น code ไม่ใช่ xml)
ในส่วน function ที่สอง ที่มีการ inject method ให้กับทุก controller
ถ้าดูตาม code แล้วจะเห็นว่ามันทำแบบนี้
code กระทัดรัดมาก มันแค่ส่งต่อ closure ที่รับเข้ามาให้กับ mailService
ถ้าเป็น java code ก็ต้องยืดยาวประมาณนี้
รู้สึกติดใจว่า ถ้ามีเวลาต้องมานั่งแกะให้เป็นเรื่องเป็นราว
วันนี้ได้ที ใน mailing list ของ th-grails-user มีปัญหาซึ่งพาดพิงถึง mail-plugin
ก็เลยจัดการ install แล้วก็นั่งแกะ code ว่ามันทำอะไรบ้าง
function หลักๆที่ mail plugin ทำก็คือ
- สร้าง service ที่ชื่อ mailService เพื่อให้ controller หรือ domain เรียกใช้ตามอัธยาศัย
โดย service นี้ จะทำหน้าที่สร้าง builder ที่จะใช้แปลง closure ที่ pass เข้ามา ให้กลายเป็น mail message
ก่อนจะ delegate ต่อให้ mailSender bean เป็นคนจัดการส่งออกไป
(mailSender แอบใช้ของที่ spring มีอยู่แล้ว นั่นคือ org.springframework.mail.javamail.JavaMailSenderImpl) - สร้าง method ที่ชื่อ sendMail ให้กับ controller ทุกตัวที่มี ผ่านทางกลไกของ metdata
code ในส่วนของ function แรกที่น่าสนใจ ก็คือการ define bean 'mailSender'
ลองดู code ที่มันใช้
def doWithSpring = {
def config = application.config.grails.mail
mailSender(JavaMailSenderImpl) {
host = config.host ?: "localhost"
defaultEncoding = config.encoding ?: "utf-8"
if(config.port)
port = config.port
if(config.username)
username = config.username
if(config.password)
password = config.password
if(config.protocol)
protocol = config.protocol
if(config.props instanceof Map && config.props)
javaMailProperties = config.props
}
}
method นี้จะถูกเรียกใช้ในช่วง startup ของ grails
ซึ่งข้างในจะเห็นว่ามันใช้ DSL ในการ config spring
code ข้างบน ถ้าเขียนในแบบดั้งเดิมของ spring ก็จะออกมาทำนองนี้
<bean id="mailSender"
class="org.springframework.mail.javamail.JavaMailSenderImpl">
<host>localhost</host>
<defaultEncoding>utf-8</defaultEncoding>
...
</bean>
ข้อได้เปรียบที่เห็นได้ชัด สำหรับการใช้ DSL ในการ config spring ก็คือ
เราสามารถใส่ logic ลงไปได้ (เพราะมันเป็น code ไม่ใช่ xml)
ในส่วน function ที่สอง ที่มีการ inject method ให้กับทุก controller
ถ้าดูตาม code แล้วจะเห็นว่ามันทำแบบนี้
def doWithApplicationContext = { applicationContext ->
configureSendMail(application, applicationContext)
}
def configureSendMail(application, applicationContext) {
application.controllerClasses*.metaClass*.sendMail = {Closure callable ->
applicationContext.mailService?.sendMail(callable)
}
}
code กระทัดรัดมาก มันแค่ส่งต่อ closure ที่รับเข้ามาให้กับ mailService
ถ้าเป็น java code ก็ต้องยืดยาวประมาณนี้
MailService svr = (MailService) ctx.getBean('mailService');
if (svr != null) {
svr.sendMail(...);
}
Related link from Roti
Tuesday, July 22, 2008
ปัญหา grails กับ xml-rpc
ใน open source project ที่กำลังทำอยู่ (ใช้ grails)
มันมี feature หนึ่งต้องสามารถรับ request เป็น xml-rpc ได้
จัดการเคาะ google หนึ่งที ก็ได้ความว่ามี plugin xmlrpc ให้ใช้
จัดการสั่ง
implement service, controller อีก ~20 บรรทัด ก็ได้ xml-rpc ฝั่ง server มาเชยชม
จากนั้นก็ทดลองเขียน xml-rpc client ด้วย python
ทดลอง run ดูก็พบว่าโลกไม่สวยงามอย่างที่คิด
มี stack trace ยอดยืดเป็นหางว่าว
debug พักใหญ่ๆ ก็ได้ความว่า มันเป็น bug ตัวนี้
http://jira.codehaus.org/browse/GRAILSPLUGINS-201
http://jira.codehaus.org/browse/GRAILS-2017
อืมม์ fixed โดยการ disable feature หนึ่งทิ้งไป
แสดงว่าเราต้องเลือกว่า อยากได้ feature ไหนมากกว่ากัน
ในเบื้องต้นเนื่องจาก xmlrpc ผมยังเป็น rpc ตัวน้อยๆอยู่
ผมก็เลยเลือกว่าจะไม่ใช้ xmlrpc plugin (ซึ่งหมายความว่าต้อง implement xmlrpc แบบง่ายๆด้วยตัวเอง)
วิธีการง่ายๆแบบนี้เลย
Update: พบปัญหาว่า กรณีมี params มากกว่า 1 ตัวแล้ว ดูเหมือนมันจะ parse ให้ผิด
ตอนนี้เลย switch ไปใช้ xml-rpc plugin แล้วทำการ disable auto xml parsing ไปก่อน
มันมี feature หนึ่งต้องสามารถรับ request เป็น xml-rpc ได้
จัดการเคาะ google หนึ่งที ก็ได้ความว่ามี plugin xmlrpc ให้ใช้
จัดการสั่ง
grails install-plugin xmlrpcimplement service, controller อีก ~20 บรรทัด ก็ได้ xml-rpc ฝั่ง server มาเชยชม
จากนั้นก็ทดลองเขียน xml-rpc client ด้วย python
ทดลอง run ดูก็พบว่าโลกไม่สวยงามอย่างที่คิด
มี stack trace ยอดยืดเป็นหางว่าว
debug พักใหญ่ๆ ก็ได้ความว่า มันเป็น bug ตัวนี้
http://jira.codehaus.org/browse/GRAILSPLUGINS-201
http://jira.codehaus.org/browse/GRAILS-2017
อืมม์ fixed โดยการ disable feature หนึ่งทิ้งไป
แสดงว่าเราต้องเลือกว่า อยากได้ feature ไหนมากกว่ากัน
ในเบื้องต้นเนื่องจาก xmlrpc ผมยังเป็น rpc ตัวน้อยๆอยู่
ผมก็เลยเลือกว่าจะไม่ใช้ xmlrpc plugin (ซึ่งหมายความว่าต้อง implement xmlrpc แบบง่ายๆด้วยตัวเอง)
วิธีการง่ายๆแบบนี้เลย
class RpcController {
def pingService
def ping = {
// ตรงนี้ grails มันจัดการแปลง xml ที่ส่งมาใน request body
// ให้อยู่ใน params object
def method = params.methodCall
def methodName = method.methodName
def methodParams = method.params
def result
if (methodName == 'ping') {
result = pingService.ping(methodParams)
} else {
result = "error: mismatch methodName ${methodName}, expect 'ping'"
}
def writer = new StringWriter()
def mkb = new groovy.xml.MarkupBuilder(writer)
mkb.methodResponse {
params {
param {
value {
string(result)
}
}
}
}
render(writer.toString())
}
}
Update: พบปัญหาว่า กรณีมี params มากกว่า 1 ตัวแล้ว ดูเหมือนมันจะ parse ให้ผิด
ตอนนี้เลย switch ไปใช้ xml-rpc plugin แล้วทำการ disable auto xml parsing ไปก่อน
Related link from Roti
Wednesday, July 16, 2008
เริ่มใช้ grails
ช่วงเดือนที่ผ่านมา ผมได้มีโอกาสสัมผัสกับ Grails อย่างจริงๆจังเป็นครั้งแรก
โดยได้มีโอกาส implement open source project ตัวหนึ่งด้วย Grails
อารมณ์ในช่วงแรก ก็คือ "wow"
สาเหตุก็คือ มันใช้ stack ทุกอย่างที่ผมคุ้นเคย และใช้อยู่แล้ว
ไม่ว่าจะเป็น spring, hibernate
แต่นำมาลด noise ด้วยการทำ DSL บ้าง หรือลด noise ด้วยคุณสมบัติของตัวภาษา groovy เองบ้าง
แถมยังยึดแนว convention over configuration ของ Rails อีก
learning curve ก็เลยถือว่าน้อยมากๆ
พอผ่านอารมณ์ wow มาได้
ก็ได้เวลาขัดอกขัดใจบ้างแล้ว
เริ่มแรกสุด ก็คือ ผมจำชื่อ package ของ java class ที่ใช้บ่อยๆไม่ได้
เดิมผมผลักภาระไปให้ IDE มัน popup หรือ import ให้เรา
แต่พอมาใช้ groovy, เจ้า context assistent ของ groovy ใน eclipse มันทำงานช้าเหลือเกิน
ความขัดใจที่สองก็คือมัน compile ช้า
เวลาเขียน unit testing เพื่อทดสอบหาแนวทางการทำงานของ library ต่างๆ (เช่น lucene, nekohtml)
การ run แต่ละครั้งมันหนึืดเหลือเกิน
แต่สิ่งที่ผมยึดถือก็คือ คนเราปรับตัวได้
อย่าปล่อยให้ความลำบากเล็กๆน้อยๆ (จากความไม่เคยชินของเรา) มาเป็นอุปสรรคในการเรียนรู้
จากข้อ 1 ที่ไหนๆ groovy plugin มันไม่ได้ช่วยอะไรเรา (แถมยังขัดขาอีก)
ก็เลยเปลี่ยนไปใช้ emacs แทน (ซึ่งไม่มี context assistent แน่ๆ)
แล้วก็เปิด javadoc ไว้ข้างๆ เพื่อใช้ค้นหาชื่อ package
แต่ก็พบว่า ถ้าเราเขียนโปรแกรมแบบไม่ระบุ type มันก็จะช่วยลด import statement ไปได้เยอะเหมือนกัน
ส่วนข้อสอง ก็แก้โดย ใช้ groovy console ทดลองเขียนให้เรียบร้อยก่อน
จากนั้นค่อย copy ไปใส่ไว้ใน unit test.
โดยได้มีโอกาส implement open source project ตัวหนึ่งด้วย Grails
อารมณ์ในช่วงแรก ก็คือ "wow"
สาเหตุก็คือ มันใช้ stack ทุกอย่างที่ผมคุ้นเคย และใช้อยู่แล้ว
ไม่ว่าจะเป็น spring, hibernate
แต่นำมาลด noise ด้วยการทำ DSL บ้าง หรือลด noise ด้วยคุณสมบัติของตัวภาษา groovy เองบ้าง
แถมยังยึดแนว convention over configuration ของ Rails อีก
learning curve ก็เลยถือว่าน้อยมากๆ
พอผ่านอารมณ์ wow มาได้
ก็ได้เวลาขัดอกขัดใจบ้างแล้ว
เริ่มแรกสุด ก็คือ ผมจำชื่อ package ของ java class ที่ใช้บ่อยๆไม่ได้
เดิมผมผลักภาระไปให้ IDE มัน popup หรือ import ให้เรา
แต่พอมาใช้ groovy, เจ้า context assistent ของ groovy ใน eclipse มันทำงานช้าเหลือเกิน
ความขัดใจที่สองก็คือมัน compile ช้า
เวลาเขียน unit testing เพื่อทดสอบหาแนวทางการทำงานของ library ต่างๆ (เช่น lucene, nekohtml)
การ run แต่ละครั้งมันหนึืดเหลือเกิน
แต่สิ่งที่ผมยึดถือก็คือ คนเราปรับตัวได้
อย่าปล่อยให้ความลำบากเล็กๆน้อยๆ (จากความไม่เคยชินของเรา) มาเป็นอุปสรรคในการเรียนรู้
จากข้อ 1 ที่ไหนๆ groovy plugin มันไม่ได้ช่วยอะไรเรา (แถมยังขัดขาอีก)
ก็เลยเปลี่ยนไปใช้ emacs แทน (ซึ่งไม่มี context assistent แน่ๆ)
แล้วก็เปิด javadoc ไว้ข้างๆ เพื่อใช้ค้นหาชื่อ package
แต่ก็พบว่า ถ้าเราเขียนโปรแกรมแบบไม่ระบุ type มันก็จะช่วยลด import statement ไปได้เยอะเหมือนกัน
ส่วนข้อสอง ก็แก้โดย ใช้ groovy console ทดลองเขียนให้เรียบร้อยก่อน
จากนั้นค่อย copy ไปใส่ไว้ใน unit test.
Related link from Roti
Tuesday, July 15, 2008
kernel stat
เมื่อวานนั่งฟัง Bart Trojanowski พูดเรื่อง "Kernel walkthrough"
ฟังได้ไม่ถึงสิบนาที ภรรยาก็บอกว่า "ปิดเถอะ ได้ยินแล้วนอนไม่หลับ ไปซื้อหูฟังกันไหม?"
หน้าที่ของสามีที่ดีก็คือ งอนแต่พองาม
สบัดหน้าเม้มปากกัดกรามแล้วก็ปิดแต่โดยดี
ถึงได้ฟังนิดหน่อย แต่ก็ได้เห็น stat บางอย่างของ Linux kernel ที่น่าสนใจ
(ตัวเลขจริงๆจำไม่ได้แล้ว แต่วันนี้เจอ blog ที่พูดถึงเรื่องนี้เหมือนกัน อยู่ที่
http://cycle-gap.blogspot.com/2008/07/linux-kernel-development-stats-from.html
ก็เลยลอกมาให้นั่งดู ประหยัดแรง ไม่ต้องไปนั่งถอดเทป
)
จำนวน changes ต่อวัน
ใน code จำนวน 9 ล้านบรรทัดของ kernel เป็น core แค่ 5%
ตัวที่มีจำนวนบรรทัดมากสุดคือ driver ล่อไปซะ 55 %
ฟังได้แค่นี้แหล่ะ ไว้ได้หูฟังมาแล้ว ค่อยฟังต่อ
แต่ตัวเลขน่าสนใจมาก (ใครไม่อยากเสียเวลาฟัง ก็ไปแอบดูใน blog ข้างบนก่อนได้เลย)
ฟังได้ไม่ถึงสิบนาที ภรรยาก็บอกว่า "ปิดเถอะ ได้ยินแล้วนอนไม่หลับ ไปซื้อหูฟังกันไหม?"
หน้าที่ของสามีที่ดีก็คือ งอนแต่พองาม
สบัดหน้าเม้มปากกัดกรามแล้วก็ปิดแต่โดยดี
ถึงได้ฟังนิดหน่อย แต่ก็ได้เห็น stat บางอย่างของ Linux kernel ที่น่าสนใจ
(ตัวเลขจริงๆจำไม่ได้แล้ว แต่วันนี้เจอ blog ที่พูดถึงเรื่องนี้เหมือนกัน อยู่ที่
http://cycle-gap.blogspot.com/2008/07/linux-kernel-development-stats-from.html
ก็เลยลอกมาให้นั่งดู ประหยัดแรง ไม่ต้องไปนั่งถอดเทป
)
จำนวน changes ต่อวัน
- เพิ่มใหม่ 4300 บรรทัด
- แก้ไข 1800 บรรทัด
- ลบทิ้ง 1500 บรรทัด
ใน code จำนวน 9 ล้านบรรทัดของ kernel เป็น core แค่ 5%
ตัวที่มีจำนวนบรรทัดมากสุดคือ driver ล่อไปซะ 55 %
ฟังได้แค่นี้แหล่ะ ไว้ได้หูฟังมาแล้ว ค่อยฟังต่อ
แต่ตัวเลขน่าสนใจมาก (ใครไม่อยากเสียเวลาฟัง ก็ไปแอบดูใน blog ข้างบนก่อนได้เลย)
Related link from Roti
Tuesday, July 08, 2008
เปิดท้าย

ผมเป็นคนที่ชอบเล่นกับเด็กเล็ก เมื่อก่อนสมัยเรียนหนังสือในมหาวิทยาลัย พอได้เวลาช่วงปิดเทอมเมื่อไร ผมก็จะไปออกค่ายสอนหนังสือเด็กๆชาวเขาที่ภาคเหนือ
หลังจากจบมาก็ไม่ได้มีกิจกรรมข้องแวะกับเด็กๆอีกเลย จนมามีลูกเป็นของตัวเอง, เมื่อลูกเริ่มถึงวัยมีเพื่อน ความสนุกเก่าๆก็หวนกลับมาอีกครั้ง, ทุกวันนี้พอตกตอนเย็น ผมก็จะเปิดประตูและกางเสื่อบนท้ายรถรอเด็กๆในหมู่บ้านแวะเวียนมาเล่นร่วมกัน
(รูปนี้แม่เด็กแอบขึ้นไปถ่ายตอนไหนก็ไม่รู้)
ปัญหาที่พบก็คือ เด็กๆมีคละวัยเหลือเกิน เจ้าเตาะแตะก็อยากเล่นแบบหนึ่ง พวกปรู๊ดปร๊าดก็อยากเล่นอีกแบบหนึ่ง
Related link from Roti
Tuesday, June 24, 2008
git-rerere
เวลาเราแตก branch ที่เรารู้ว่าเป็นหนังชีวิต (branch ที่มีอายุยาวๆ)
เรามักจะต้องคอย merge ตัว master เข้ามาที่ branch เรา เพื่อที่จะตรวจสอบ conflict ต่างๆที่เกิดขึ้น
ซึ่งมีศัพท์เรียกกันว่า "test merge"
ลองดูรูปประกอบข้างล่าง
ในที่นี่ topic ก็คือ branch (ที่อายุยืน) ของเรา
เครื่องหมาย '*' ก็คือ จุดที่ทั้ง topic และ master แตะเนื้อหาที่เดียวกัน (เป็นจุดที่เวลา merge แล้วจะเกิด conflict )
เครื่องหมาย '+' ก็คือ test merge ที่เกิดขึ้น (และได้ทำการ solve conflict ไว้แล้ว)
เมื่อเรา merge topic กลับไปยัง master,
commit ของ test merge ก็จะถูกเก็บไว้ใน history ของ master ไปด้วย
Note: รูปประกอบตัดมาจาก document ของ git
สำหรับบางคนประเด็นนี้ถือเป็นประเด็นที่สำคัญ
เช่น linus เขาเรียกเจ้า "test merge" นี้ว่า "useless merge"
และเห็นว่ากันว่า เขามักจะ reject เจ้า merge branch ที่มีเจ้า "test merge" ติดเข้ามาด้วย
แล้วทำอย่างไร ถึงจะไม่ให้มี test-merge ติดเข้ามาหล่ะ
วิธีที่เขาทำกันก็คือ
ยังทำ test-merge เหมือนเดิม แต่เมื่อ merge เสร็จแล้ว ก็จัดการลบ commit นั้นทิ้งเสีย ด้วยคำสั่ง
ผลที่ได้ก็คือ เวลา merge topic กลับเข้า master
เราก็จะได้ tree หน้าตาเกลี้ยงเกลาแบบนี้
แต่ชีวิตไม่ได้โรยด้วยกลีบกุหลาบ
ปัญหาที่ตามมาก็คือ ไอ้เจ้าพวก conflict ที่เราเคย solve ตอน test merge
มันจะตามกลับมาให้เราแก้ไขอีกครั้งตอน merge topic กลับไปยัง master
ซึ่งการแก้ไขสองรอบแบบนี้ไม่สนุกแน่ๆ
โชคดีที่ git มีทางออกให้เรา
คำสั่งที่เป็นพระเอกก็คือคำสั่ง git-rerere
หลังจาก merge แล้วเกิด conflict ขึ้น
ให้สั่ง git-rerere ก่อนที่จะแก้ไข conflict
และหลังจากแก้ไข conflict เสร็จแล้ว ก็ให้สั่ง git-rerere อีกที
ผลก็คือ เจ้า git จะแอบจำวิธี solve conflict ของเราไว้
ทำให้ครั้งต่อไปที่เกิด conflict แบบนี้ขึ้นมาอีก (test merge ครั้งถัดไป หรือตอน merge topic กลับ master)
มันจะจัดการ resolve ให้โดยอัติโนมัติ
โดย default แล้ว git-rerere ไม่ได้ถูก enable ไว้
เราสามารถสั่ง enable feature นี้โดยการเข้าไปสร้าง directory rr-cache ไว้ใต้ .git directory
เรามักจะต้องคอย merge ตัว master เข้ามาที่ branch เรา เพื่อที่จะตรวจสอบ conflict ต่างๆที่เกิดขึ้น
ซึ่งมีศัพท์เรียกกันว่า "test merge"
ลองดูรูปประกอบข้างล่าง
ในที่นี่ topic ก็คือ branch (ที่อายุยืน) ของเรา
เครื่องหมาย '*' ก็คือ จุดที่ทั้ง topic และ master แตะเนื้อหาที่เดียวกัน (เป็นจุดที่เวลา merge แล้วจะเกิด conflict )
เครื่องหมาย '+' ก็คือ test merge ที่เกิดขึ้น (และได้ทำการ solve conflict ไว้แล้ว)
เมื่อเรา merge topic กลับไปยัง master,
commit ของ test merge ก็จะถูกเก็บไว้ใน history ของ master ไปด้วย
$ git checkout topic
$ git merge master
$ ... work on both topic and master branches
$ git checkout master
$ git merge topic
o---*---o---+---o---o topic
/ / \
o---o---o---*---o---o---o---o---+ master
Note: รูปประกอบตัดมาจาก document ของ git
สำหรับบางคนประเด็นนี้ถือเป็นประเด็นที่สำคัญ
เช่น linus เขาเรียกเจ้า "test merge" นี้ว่า "useless merge"
และเห็นว่ากันว่า เขามักจะ reject เจ้า merge branch ที่มีเจ้า "test merge" ติดเข้ามาด้วย
แล้วทำอย่างไร ถึงจะไม่ให้มี test-merge ติดเข้ามาหล่ะ
วิธีที่เขาทำกันก็คือ
ยังทำ test-merge เหมือนเดิม แต่เมื่อ merge เสร็จแล้ว ก็จัดการลบ commit นั้นทิ้งเสีย ด้วยคำสั่ง
git reset --hard HEAD^ผลที่ได้ก็คือ เวลา merge topic กลับเข้า master
เราก็จะได้ tree หน้าตาเกลี้ยงเกลาแบบนี้
o---*---o-------o---o topic
/ \
o---o---o---*---o---o---o---o---+ master
แต่ชีวิตไม่ได้โรยด้วยกลีบกุหลาบ
ปัญหาที่ตามมาก็คือ ไอ้เจ้าพวก conflict ที่เราเคย solve ตอน test merge
มันจะตามกลับมาให้เราแก้ไขอีกครั้งตอน merge topic กลับไปยัง master
ซึ่งการแก้ไขสองรอบแบบนี้ไม่สนุกแน่ๆ
โชคดีที่ git มีทางออกให้เรา
คำสั่งที่เป็นพระเอกก็คือคำสั่ง git-rerere
หลังจาก merge แล้วเกิด conflict ขึ้น
ให้สั่ง git-rerere ก่อนที่จะแก้ไข conflict
และหลังจากแก้ไข conflict เสร็จแล้ว ก็ให้สั่ง git-rerere อีกที
ผลก็คือ เจ้า git จะแอบจำวิธี solve conflict ของเราไว้
ทำให้ครั้งต่อไปที่เกิด conflict แบบนี้ขึ้นมาอีก (test merge ครั้งถัดไป หรือตอน merge topic กลับ master)
มันจะจัดการ resolve ให้โดยอัติโนมัติ
โดย default แล้ว git-rerere ไม่ได้ถูก enable ไว้
เราสามารถสั่ง enable feature นี้โดยการเข้าไปสร้าง directory rr-cache ไว้ใต้ .git directory
Related link from Roti
Friday, June 20, 2008
Java, Parallel, Monad
เห็น code java นี้แล้ว ธาตุไฟแทรก
ใครธาตุแข็งแรงเชิญไปอ่านได้ที่นี่
Higher-Order Java Parallelism, Part 1: Parallel Strategies and the Callable Monad
public static <A, B> F<Callable<A>, Callable<B>> fmap(final F<A, B> f) {
return new F<Callable<A>, Callable<B>>() {
public Callable<B> f(final Callable<A> a) {
return bind(a, new F<A, Callable<B>>() {
public Callable<B> f(final A ab) {
return new Callable<B>() {
public B call() {
return f.f(ab);
}
};
}
});
}
};
}
ใครธาตุแข็งแรงเชิญไปอ่านได้ที่นี่
Higher-Order Java Parallelism, Part 1: Parallel Strategies and the Callable Monad
Related link from Roti
Wednesday, June 11, 2008
merge อย่างไรดี
ปัญหาหนึ่งที่ Orangegears เจอก็คือ เนื่องจากเรา fork ออกมาจาก Ofbiz
แต่ก็ยังต้องการ sync กับ Ofbiz อย่างไกล้ชิด (ไม่เหมือน Opentap ที่แยกออกไปอย่างชัดเจน)
ทำให้เราต้องคอย merge code จาก Ofbiz เข้ามายัง Orangegears เป็นระยะๆ
วิธีการเดิมที่น้อง sand ใช้ ก็คือใช้ kdiff3 ทำการ merge
ซึ่งก็สะดวกดี เพราะมี UI สวยงาม
แต่ผมก็เจอปัญหาว่า changed ของผมมักจะหายไปบ่อยๆ
ผมก็เลยมองหาวิธีใหม่ๆมาเรื่อยๆ
วันก่อนหลังจากลองเล่น multiple branches ใน git ดู
ก็พบว่า git ยืดหยุ่นพอที่เราจะทำ multiple remote branch จาก svn repository มากกว่า 1 ที่ได้
ผมก็เลยทดลอง merge ด้วยวิธีนี้ดู
วิธีการก็คือ
เริ่มด้วยการสร้าง git repository ที่มี link ชี้ไปยัง project ofbiz ก่อน
หลังจากสั่งคำสั่งนี้ git จะสร้าง working directory เปล่าๆให้ (ยังไม่ fetch code มาให้)
โดย file .git/config จะมีหน้าตาแบบนี้
เราก็ทำการจัดแจงแก้ไขชื่อให้เหมาะสม จะได้ไม่งงภายหลัง
และทำการเพิ่ม repository ของ Ofbiz เข้าไป
จากนั้นก็ทำการ fetch ข้อมูลทีละ repository
เริ่มจาก ofbiz ก่อน เอา revision ล่าสุดเลย ไม่เอา history
Note1: เลข revision ของ ofbiz นี่ล่อไปหลักหกแสนแล้ว
ทั้งนี้เพราะ repo ของ apache เขาใช้ share ร่วมกันทุก project
Note2: ผมลอง fetch orangegears ก่อน ปรากฎว่า fetch ofbiz ไม่ได้ (ไม่มี error ด้วย)
ตามด้วย orangegears โดยเริ่มต้นที่ revision 142 เลย ไม่ต้องย้อนอดีตมากนัก
ลองสั่ง git branch -r จะเห็นว่ามี og_trunk กับ ofbiz_trunk เกิดขึ้น
โดย default trunk ของ ofbiz จะถูก map เข้ามาเป็น master ใน local branch
ทำการเปลี่ยนชื่อให้เรียบร้อย จะได้ไม่งงว่าใครเป็นใคร
ส่วน og_trunk นั้นยังไม่มี local branch ต้องทำการสั่ง
ขั้นตอนการ merge
fetch code จาก ofbiz ให้ up-to-date ก่อน
fetch code ของ orangegears ให้ up-to-date เช่นเดียวกัน
เตรียม branch สำหรับ merge โดยสร้าง branch แยกออกจาก og (ไม่จำเป็น แต่ก็ควรทำเป็นนิสัย)
สั่ง merge
ที่ยากก็คือเวลาเกิด conflict ก็ต้องตามแก้ไขให้เรียบร้อยก่อน
Note1: สำหรับผม ผมเลือกใช้ emacs + git-emacs mode ซึ่งมันจะเรียกใช้ ediff ในการ solve conflict
Note2: คิดว่าการ merge ครั้งแรก จะมี conflict เยอะหน่อย
แต่พอเป็นการ merge ครั้งที่ 2.. จะมี conflict น้อยลง เพราะว่า branch ทั้งสองมี history ที่เชื่อมกันแล้ว
(เป็นผลดีต่อ three-way merge)
switch กลับไปยัง og และทำการ merge
จากนั้นก็สั่ง commit กลับขึ้น svn repository
สุดท้ายก็ลบ temporary branch ทิ้ง
ไว้จะทดลองทำสักระยะหนึ่ง (โดยยังไม่ commit ผลลัพท์จากการ merge กลับขึ้น orangegears)
เพื่อดูว่ามันมีประสิทธิภาพแค่ไหนก่อน
แต่ก็ยังต้องการ sync กับ Ofbiz อย่างไกล้ชิด (ไม่เหมือน Opentap ที่แยกออกไปอย่างชัดเจน)
ทำให้เราต้องคอย merge code จาก Ofbiz เข้ามายัง Orangegears เป็นระยะๆ
วิธีการเดิมที่น้อง sand ใช้ ก็คือใช้ kdiff3 ทำการ merge
ซึ่งก็สะดวกดี เพราะมี UI สวยงาม
แต่ผมก็เจอปัญหาว่า changed ของผมมักจะหายไปบ่อยๆ
ผมก็เลยมองหาวิธีใหม่ๆมาเรื่อยๆ
วันก่อนหลังจากลองเล่น multiple branches ใน git ดู
ก็พบว่า git ยืดหยุ่นพอที่เราจะทำ multiple remote branch จาก svn repository มากกว่า 1 ที่ได้
ผมก็เลยทดลอง merge ด้วยวิธีนี้ดู
วิธีการก็คือ
เริ่มด้วยการสร้าง git repository ที่มี link ชี้ไปยัง project ofbiz ก่อน
git svn init http://svn.apache.org/repos/asf/ofbiz/trunk
หลังจากสั่งคำสั่งนี้ git จะสร้าง working directory เปล่าๆให้ (ยังไม่ fetch code มาให้)
โดย file .git/config จะมีหน้าตาแบบนี้
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[svn-remote "svn"]
url = http://svn.apache.org/repos/asf/ofbiz/trunk
fetch = :refs/remotes/trunk
เราก็ทำการจัดแจงแก้ไขชื่อให้เหมาะสม จะได้ไม่งงภายหลัง
และทำการเพิ่ม repository ของ Ofbiz เข้าไป
[svn-remote "ofbiz"]
url = http://svn.apache.org/repos/asf/ofbiz/trunk
fetch = :refs/remotes/ofbiz_trunk
[svn-remote "orangegears"]
url = https://orangegears.svn.sourceforge.net/svnroot/orangegears
fetch = trunk:refs/remotes/og_trunk
จากนั้นก็ทำการ fetch ข้อมูลทีละ repository
เริ่มจาก ofbiz ก่อน เอา revision ล่าสุดเลย ไม่เอา history
Note1: เลข revision ของ ofbiz นี่ล่อไปหลักหกแสนแล้ว
ทั้งนี้เพราะ repo ของ apache เขาใช้ share ร่วมกันทุก project
Note2: ผมลอง fetch orangegears ก่อน ปรากฎว่า fetch ofbiz ไม่ได้ (ไม่มี error ด้วย)
git svn fetch -r 666189:HEAD ofbiz
ตามด้วย orangegears โดยเริ่มต้นที่ revision 142 เลย ไม่ต้องย้อนอดีตมากนัก
git svn fetch -r 142:HEAD orangegears
ลองสั่ง git branch -r จะเห็นว่ามี og_trunk กับ ofbiz_trunk เกิดขึ้น
pphetra@mypann:~/projects/java/t$ git branch -r
ofbiz_trunk
og_trunk
โดย default trunk ของ ofbiz จะถูก map เข้ามาเป็น master ใน local branch
ทำการเปลี่ยนชื่อให้เรียบร้อย จะได้ไม่งงว่าใครเป็นใคร
git branch -m master ofbiz
ส่วน og_trunk นั้นยังไม่มี local branch ต้องทำการสั่ง
git checkout -b og og_trunk
ขั้นตอนการ merge
fetch code จาก ofbiz ให้ up-to-date ก่อน
git checkout -f ofbiz
git svn rebase
fetch code ของ orangegears ให้ up-to-date เช่นเดียวกัน
git checkout -f og
git svn rebase
เตรียม branch สำหรับ merge โดยสร้าง branch แยกออกจาก og (ไม่จำเป็น แต่ก็ควรทำเป็นนิสัย)
git checkout -b merge-ofbiz
สั่ง merge
git merge ofbiz
ที่ยากก็คือเวลาเกิด conflict ก็ต้องตามแก้ไขให้เรียบร้อยก่อน
Note1: สำหรับผม ผมเลือกใช้ emacs + git-emacs mode ซึ่งมันจะเรียกใช้ ediff ในการ solve conflict
Note2: คิดว่าการ merge ครั้งแรก จะมี conflict เยอะหน่อย
แต่พอเป็นการ merge ครั้งที่ 2.. จะมี conflict น้อยลง เพราะว่า branch ทั้งสองมี history ที่เชื่อมกันแล้ว
(เป็นผลดีต่อ three-way merge)
switch กลับไปยัง og และทำการ merge
git checkout -f og
git merge merge-ofbiz
จากนั้นก็สั่ง commit กลับขึ้น svn repository
git svn dcommit
สุดท้ายก็ลบ temporary branch ทิ้ง
git branch -D merge-ofbiz
ไว้จะทดลองทำสักระยะหนึ่ง (โดยยังไม่ commit ผลลัพท์จากการ merge กลับขึ้น orangegears)
เพื่อดูว่ามันมีประสิทธิภาพแค่ไหนก่อน
Related link from Roti
Tuesday, June 10, 2008
ใช้ git จัดการ svn branches
ช่วงนี้ project ผมซึ่งใช้ subversion เป็น repository เริ่มมีการแตก branch เยอะขึ้น
ส่งผลให้คนที่ดูหลาย branch เกิดความลำบากในการ switch ไปมาระหว่าง branch มากขึ้น
ปกติวิธีการ switch branch เราสามารถใช้คำสั่ง
แต่ปัญหาก็คือมันมักจะมี code ที่กำลังแก้ค้างอยู่ จะ commit ไว้่ก่อน switch ก็ไม่เหมาะ เพราะยังแก้ไขไม่ทันเสร็จดี
ผมเลือกเอา git มาช่วยจัดการปัญหานี้
เริ่มแรกสุดก็คือ ในตอนที่เราสั่ง svn clone, เราต้องระบุ flag เพิ่มดังนี้
ผลที่ได้ ก็คือ master branch ของเราจะ map เข้ากับ trunk ของ svn
ส่วน branches และ tags ต่างๆที่อยู่ใน subversion repository จะมีสถานะ เป็น remote branch ใน git
สมมติว่าเราต้องการจะทำงานกับ branch j1023
เราก็จะต้องทำการสร้าง local branch ที่ map เข้ากับ remote branch ด้วยคำสั่งนี้
ถ้ามีงานด่วนเข้ามา ระหว่างทำงาน ก็เลือกได้ว่า จะ commit เข้าไปก่อน (กลับมา revert ทีหลังได้ หรือใช้ commit --amend เพื่อรวบยอด commit ภายหลังก็ได้)
หรือถ้าไม่อยาก commit เลย ก็อาจจะใช้ git-stash แทนก็ได้
พอ clear state ของ working copy เสร็จ ก็ให้สั่ง switch โดยใช้คำสั่ง
การ update branch และ trunk ให้เท่ากับ svn repository ทำได้โดยใช้คำสั่ง
ผลของมัน ก็คือ git จะ fetch changed (ของทุกๆ branches, tags) ที่เกิดขึ้นบน svn repo มาที่ git repository
แต่จะยังไม่ apply changed เข้ากับ local branch
ถ้าต้องการ apply changed เข้ากับ local branch เราต้องสั่ง
ส่งผลให้คนที่ดูหลาย branch เกิดความลำบากในการ switch ไปมาระหว่าง branch มากขึ้น
ปกติวิธีการ switch branch เราสามารถใช้คำสั่ง
svn switch ได้เลยแต่ปัญหาก็คือมันมักจะมี code ที่กำลังแก้ค้างอยู่ จะ commit ไว้่ก่อน switch ก็ไม่เหมาะ เพราะยังแก้ไขไม่ทันเสร็จดี
ผมเลือกเอา git มาช่วยจัดการปัญหานี้
เริ่มแรกสุดก็คือ ในตอนที่เราสั่ง svn clone, เราต้องระบุ flag เพิ่มดังนี้
git svn clone http://your-repo -T trunk -b branches -t tags
ผลที่ได้ ก็คือ master branch ของเราจะ map เข้ากับ trunk ของ svn
ส่วน branches และ tags ต่างๆที่อยู่ใน subversion repository จะมีสถานะ เป็น remote branch ใน git
$ git branch
* master
pphetra@pann@[~/projects/java/gitwcfweb]
$ git branch -r
c1001
j1023
j1027
j1039
j1041
trunk
สมมติว่าเราต้องการจะทำงานกับ branch j1023
เราก็จะต้องทำการสร้าง local branch ที่ map เข้ากับ remote branch ด้วยคำสั่งนี้
git checkout -b j1023-local j1023
ถ้ามีงานด่วนเข้ามา ระหว่างทำงาน ก็เลือกได้ว่า จะ commit เข้าไปก่อน (กลับมา revert ทีหลังได้ หรือใช้ commit --amend เพื่อรวบยอด commit ภายหลังก็ได้)
หรือถ้าไม่อยาก commit เลย ก็อาจจะใช้ git-stash แทนก็ได้
พอ clear state ของ working copy เสร็จ ก็ให้สั่ง switch โดยใช้คำสั่ง
git checkout -f master
การ update branch และ trunk ให้เท่ากับ svn repository ทำได้โดยใช้คำสั่ง
git svn fetch
ผลของมัน ก็คือ git จะ fetch changed (ของทุกๆ branches, tags) ที่เกิดขึ้นบน svn repo มาที่ git repository
แต่จะยังไม่ apply changed เข้ากับ local branch
ถ้าต้องการ apply changed เข้ากับ local branch เราต้องสั่ง
git svn rebase
Related link from Roti
Wednesday, June 04, 2008
Structural Type
เมื่อก่อนเวลาเขียนโปรแกรมใน Java, สิ่งแรกที่นึกขึ้นมาในหัวก็คือการกำหนด Interface
ยังขำที่โปรแกรม ruby แรกที่เขียน ก็พยายามจะ define interface ทั้งๆที่ ruby มันไม่มี interface แถมยังทำ duck typing ได้
วันก่อนอ่านเจอ feature ของ scala ที่ชื่อ Structural types ใน Scala
รู้สึกว่า งามจริงๆ
ดูตัวอย่างการใช้ Structural Type
Note: สำหรับคนที่ไม่คุ้นกับ Scala
def คือการกำหนด method, เครื่องหมาย : คือการกำหนด type
กรณี code ข้างล่างนี้, method say มี return type เป็น String
ส่วน
ยังขำที่โปรแกรม ruby แรกที่เขียน ก็พยายามจะ define interface ทั้งๆที่ ruby มันไม่มี interface แถมยังทำ duck typing ได้
วันก่อนอ่านเจอ feature ของ scala ที่ชื่อ Structural types ใน Scala
รู้สึกว่า งามจริงๆ
ดูตัวอย่างการใช้ Structural Type
class Person {
def say():String = "hi"
}
class Duck {
def say():String = "Quack"
}
object Test {
def play(element: {def say():String}) = {
System.out.println(element.say());
}
def main(args : Array[String]) : Unit = {
play(new Person())
play(new Duck())
}
}
Note: สำหรับคนที่ไม่คุ้นกับ Scala
def คือการกำหนด method, เครื่องหมาย : คือการกำหนด type
กรณี code ข้างล่างนี้, method say มี return type เป็น String
def say():String = "Quack"
ส่วน
Object {...} ก็คือ Singleton Object
Related link from Roti
Monday, June 02, 2008
Groovy in Ofbiz
น้องแซนแจ้งมาว่าขณะที่ merge source code ของ Ofbiz เข้า project Orangegears
พบว่ามี้ groovy code โผล่เข้ามาแล้วแล้ว
ว่าแล้วผมก็จัดแจง update source code ของ orangegears เสียหน่อย
แล้วก็สั่ง grep -ilR groovy ดู
ก็พบว่าเริ่มมีการ replace screen action script จากของเดิมที่เขียนด้วย bsh ไปเป็น groovy บ้างแล้ว
แล้วก็พบว่ามีการเตรียมการใช้ groovy ใน service layer อีกด้วย (แต่ยังไม่ได้มีการ implement)
ลองไล่เปรียบเทียบ syntax ของ bsh กับ groovy ดูว่า ช่วยลดรูปอะไรได้บ้าง
ใน ofbiz เวลา pass parameters มักจะใช้ Map ในการ pass arguments
พอเปลี่ยนเป็น groovy แล้วการสร้าง Map ก็เลยกระทัดรัดขึ้น
แน่นอนพวกการ iterate collections นี่ได้ประโยชน์ไปเต็มๆ
การอ้างถึง value ใน Map
ด้วย syntax sugar ของ Groovy ก็เลย สะอาดสะอ้านขึ้นแบบนี้
การ check empty หรือ null collections ก็สบายตาขึ้น
พบว่ามี้ groovy code โผล่เข้ามาแล้วแล้ว
ว่าแล้วผมก็จัดแจง update source code ของ orangegears เสียหน่อย
แล้วก็สั่ง grep -ilR groovy ดู
ก็พบว่าเริ่มมีการ replace screen action script จากของเดิมที่เขียนด้วย bsh ไปเป็น groovy บ้างแล้ว
แล้วก็พบว่ามีการเตรียมการใช้ groovy ใน service layer อีกด้วย (แต่ยังไม่ได้มีการ implement)
ลองไล่เปรียบเทียบ syntax ของ bsh กับ groovy ดูว่า ช่วยลดรูปอะไรได้บ้าง
ใน ofbiz เวลา pass parameters มักจะใช้ Map ในการ pass arguments
พอเปลี่ยนเป็น groovy แล้วการสร้าง Map ก็เลยกระทัดรัดขึ้น
// bsh
payment = delegator.findByPrimaryKey("Payment",
UtilMisc.toMap("paymentId", paymentId)));
# groovy
payment = delegator.findByPrimaryKey("Payment", [paymentId : paymentId]);
แน่นอนพวกการ iterate collections นี่ได้ประโยชน์ไปเต็มๆ
// bsh
oibIter = orderItemBillings.iterator();
while (oibIter.hasNext()) {
orderIb = oibIter.next();
orders.add(orderIb.getString("orderId"));
}
# groovy
orderItemBillings.each { orderIb ->
orders.add(orderIb.orderId);
}
การอ้างถึง value ใน Map
ด้วย syntax sugar ของ Groovy ก็เลย สะอาดสะอ้านขึ้นแบบนี้
// bsh
context.put("decimals", decimals);
context.put("rounding", rounding);
# groovy
context.decimals = decimals;
context.rounding = rounding;
การ check empty หรือ null collections ก็สบายตาขึ้น
// bsh
if (glAccounts != null && glAccounts.size() > 0) {
glAccount = glAccounts.get(0);
# groovy
if (glAccounts) {
glAccount = glAccounts[0];
Related link from Roti
Friday, May 30, 2008
My Pyhton 's process was Killed
ช่วงนี้กำลังทดสอบโปรแกรมที่เขียนด้วย python บนเครื่อง Production ที่ใช้ AIX เป็น OS
หลังจาก run program ไปได้พักหนึ่ง, โปรแกรมก็หยุดทำงานพร้อมกับมีข้อความแบบนี้ต่อท้าย
คำถามแรกก็คือ "ใคร kill กูวะ"
process ของน้องชิ้ม (น้องที่ทำงาน) ตกเป็นผู้ต้องสงสัยรายแรก
(น้องชิ้มเขียน script ที่คอย monitor ว่ามี process ไหนใช้ cpu ผิดปกติบ้าง
ถ้าเจอก็จะจัดการ kill เสีย)
หลังจากน้องชิ้มตรวจดู log file สักพัก ก็บอกว่า "script ผมไม่ได้ทำครับพี่"
ผู้ต้องสงสัยรายถัดไป ก็คือ message ข้างล่างนี้
message นี้เกิดขึ้นในระหว่างทำงาน
หลังจากค้น google ก็พบว่า kernel น่าจะเป็นคนสั่ง kill process เอง (http://tinyurl.com/59e7yw)
ส่วนสำเหตุก็คือ bug ตัวนี้ http://bugs.python.org/issue1234
นัยว่าเจ้า python มันคงเรียกใช้ sem_wait มากเกินไป จน kernel มันทนไม่ได้
ว่าแล้วก็รอแปะ patch และ compile python เย็นนี้
จันทร์หน้ามารอดูผลกันใหม่
หลังจาก run program ไปได้พักหนึ่ง, โปรแกรมก็หยุดทำงานพร้อมกับมีข้อความแบบนี้ต่อท้าย
killed
คำถามแรกก็คือ "ใคร kill กูวะ"
process ของน้องชิ้ม (น้องที่ทำงาน) ตกเป็นผู้ต้องสงสัยรายแรก
(น้องชิ้มเขียน script ที่คอย monitor ว่ามี process ไหนใช้ cpu ผิดปกติบ้าง
ถ้าเจอก็จะจัดการ kill เสีย)
หลังจากน้องชิ้มตรวจดู log file สักพัก ก็บอกว่า "script ผมไม่ได้ทำครับพี่"
ผู้ต้องสงสัยรายถัดไป ก็คือ message ข้างล่างนี้
sem_trywait: Permission denied
sem_wait: Permission denied
sem_post: Permission denied
message นี้เกิดขึ้นในระหว่างทำงาน
หลังจากค้น google ก็พบว่า kernel น่าจะเป็นคนสั่ง kill process เอง (http://tinyurl.com/59e7yw)
ส่วนสำเหตุก็คือ bug ตัวนี้ http://bugs.python.org/issue1234
นัยว่าเจ้า python มันคงเรียกใช้ sem_wait มากเกินไป จน kernel มันทนไม่ได้
ว่าแล้วก็รอแปะ patch และ compile python เย็นนี้
จันทร์หน้ามารอดูผลกันใหม่
Related link from Roti
เปิดเน็ต เปิดใจ
ที่บ้านผมไม่มีทีวี แล้วก็ไม่ได้รับหนังสือพิมพ์ ก็เลยไม่ตามข่าวการเมืองอย่างไกล้ชิด
แต่ก็รู้ว่า ประชาธิปัตย์ ปัจจุบันแม้จะผ่านไป 50-60 ปีแล้ว ยังเล่นมุขเดิมไม่เลิก
เรื่องที่ไกล้ตัวหน่อยก็มี กรณีนายเทพไท เสนพงศ์ ออกมาสาดโคลนใส่เว็บ
เห็นมีมหาวิทยาลัยเที่ยงคืนรวมอยู่ด้วยแล้วอดรนทนไม่ได้
ก็เลยต้องขอร่วมลงชื่อแสดงเสียงสักหน่อย

ปกป้องเสรีภาพของเรา
บนอินเทอร์เน็ตของเรา
ร่วมลงชื่อในแถลงการณ์
แต่ก็รู้ว่า ประชาธิปัตย์ ปัจจุบันแม้จะผ่านไป 50-60 ปีแล้ว ยังเล่นมุขเดิมไม่เลิก
เรื่องที่ไกล้ตัวหน่อยก็มี กรณีนายเทพไท เสนพงศ์ ออกมาสาดโคลนใส่เว็บ
เห็นมีมหาวิทยาลัยเที่ยงคืนรวมอยู่ด้วยแล้วอดรนทนไม่ได้
ก็เลยต้องขอร่วมลงชื่อแสดงเสียงสักหน่อย
ปกป้องเสรีภาพของเรา
บนอินเทอร์เน็ตของเรา
ร่วมลงชื่อในแถลงการณ์
Related link from Roti
Tuesday, May 27, 2008
Pyro
ช่วงนี้มีความจำเป็นต้องใช้ remote call บน python, ค้น google ดูก็พบเจ้า Pyro
หลังจากอ่านหลักการแล้วก็อ๋อ เพราะทำงานแนวเดิียวกับ java RMI
หลักการทำงาน
สิ่งที่ต้องระวังในการ implement remote object ของเราก็คือ
มันต้องเป็น thread safe เนื่องจาก daemon จะใช้วิธีแตก thread เมื่อมี incoming connection วิ่งเข้ามา
feature ที่น่าสนใจในประเด็นนี้ ก็คือ TLS (Thread Local Storage)
ซึ่งช่วยให้เราเก็บข้อมูลโดยการ bind local data เข้ากับ thread แทน
feature ที่น่าสนใจอีกอย่างก็คือ Mobile code
case นี้เป็นกรณีที่ client call ไปยัง remote object โดยส่ง argument เป็น object ที่ไม่มี code อยู่บน server มาด้วย
ซึ่งโดยปกติ มันจะเกิด error ประเภท NoModuleError
แต่ถ้าเรากำหนด configuration ให้ Pyro ใช้ feature Mobile code
เวลาที่ server เจอ code ที่ไม่รู้จัก มันก็จะ request code มายัง client
กรณี mobile code นี้ support 2-way
นั่นคือ support กรณี server return object ที่ไม่มี code บน client ด้วย
หลังจากอ่านหลักการแล้วก็อ๋อ เพราะทำงานแนวเดิียวกับ java RMI
หลักการทำงาน
- Name Server
เพื่อให้ client สามารถ lookup service ได้ง่ายๆ, Pyro ก็เลย provide Name Server มาให้ด้วย
เจ้า name server ที่ pyro ให้มา มันแบ่งออกเป็น 2 ประเภทคือ- Regular, non-persistent
ตัวนี้พอ name server process ตาย, ค่าต่างๆใน registry ก็หายไปด้วย - Persistent
ค่าต่างๆใน registry จะเก็บไว้บน disk
เพื่อเพิ่ม availability, เจ้าตัว name server นี้ ยังสามารถ start ในแบบ Paired mode ได้อีกด้วย โดยทั้งคู่จะทำ replicate registry ซึ่งกันและกันไว้ - Regular, non-persistent
- Client
การที่ client จะติดต่อ server ได้นั้น ขั้นแรกก็ต้องหา Name Server ให้เจอเสียก่อน
วิธีการหา Name Server ก็คือlocator = Pyro.naming.NameServerLocator()
ns = locator.getNS()
ขั้นตอนการทำงานภายในก็คือ มันจะทำการ broadcast message ออกไป
เจ้า Name server (ซึ่ง implement broadcast listener) ก็จะตอบกลับมา
Note: กรณีของผม ผมลองใช้ boardcast บน production server แล้ว, message มันหายต๋อมไป (ด้วยความขี้เกียจไปไล่หาสาเหตุ)
ผมก็เลย config ให้ NameServerLocator มันต่อตรงไปที่ Name Server โดยตรงเลย แทนที่จะ broadcast
การ config ให้ต่อตรงทำได้โดยPyro.config.PYRO_NS_HOSTNAME='YOUR_HOSTNAME'
หลังจากหา Name Server เจอแล้ว ขั้นถัดไปก็คือ ทำการถามหา URI ของ server ที่ต้องการuri = ns.resolve('my_service')
เมื่อได้ uri แล้ว สุดท้ายก็คือทำการสร้าง proxy object ซึ่งเจ้า Pyro แบ่งประเภท Proxy ออกเป็น 2 แบบคือ- Proxy ธรรมดา
- Proxy ที่สามารถ access attribute ของ remote object ได้ด้วย
วิธีการสร้าง proxy ก็คือobj = uri.getProxy()
# or
obj = uri.getAttrProxy()
ที่เหลือ ก็เป็นการเรียกใช้ method ต่างๆบน remote object ที่เราได้มา - Proxy ธรรมดา
- Server
การทำงานฝั่ง server เริ่มต้นด้วยการสร้าง daemon object
(มี parameter เป็น name server object ซึ่ง lookup มาด้วยวิธีเดียวกันกับ client)daemon = Pyro.core.Daemon()
daemon.useNameServer(ns)
ข้อควรระวังก็คือ ต้องระวังเรื่อง reference ถึง object daemon ของเรา
มิเช่นนั้น garbage collection อาจกวาด daemon เราทิ้งไปได้
หลังจากได้ daemon มา ก็ทำการสร้าง Object instance ที่ต้องการให้ client ต่อใช้
เนื่องจาก pyro ต้องหลอก object ของเราว่ามันทำงานเหมือนกับอยู่ในสภาพแวดล้อมแบบ stand-alone
ดังนั้น Remote Object ของเราก็เลยต้องถูกห่อไว้ใน Pyro.core.ObjBase
ซึ่งเราสามารถทำได้ 3 วิธีคือ- ให้ Remote class ของเรา extend Pyro.core.ObjBase ตรงๆเลย
- delegate pattern
บางครั้งเราอยากเขียน Remote Class โดยไม่อยากให้มี dependency ถึง Pyro เลยobj = Pyro.core.ObjBase()
myservice = MyService()
obj.delegateTo(myservice) - สร้าง class ใหม่ที่ extend ทั้ง Pyro.core.ObjBase และ Service class ของเรา
class ServiceImpl(Pyro.core.ObjBase, MyService):
def __init__(self):
Pyro.core.ObjBase.__init__(self)
MyService.__init__(self)
ขั้นถัดไปก็คือทำการ binding
โดยสั่ง connect daemon กับ Object instance
ซึ่งเจ้า daemon จะจัดการไปคุยกับ Name Server ให้เราเองdaemon.connect(obj, 'my_service')
สุดท้ายก็คือการสั่งให้ daemon วน loop รับ request จาก clientdaemon.requestLoop()
- ให้ Remote class ของเรา extend Pyro.core.ObjBase ตรงๆเลย
สิ่งที่ต้องระวังในการ implement remote object ของเราก็คือ
มันต้องเป็น thread safe เนื่องจาก daemon จะใช้วิธีแตก thread เมื่อมี incoming connection วิ่งเข้ามา
feature ที่น่าสนใจในประเด็นนี้ ก็คือ TLS (Thread Local Storage)
ซึ่งช่วยให้เราเก็บข้อมูลโดยการ bind local data เข้ากับ thread แทน
feature ที่น่าสนใจอีกอย่างก็คือ Mobile code
case นี้เป็นกรณีที่ client call ไปยัง remote object โดยส่ง argument เป็น object ที่ไม่มี code อยู่บน server มาด้วย
ซึ่งโดยปกติ มันจะเกิด error ประเภท NoModuleError
แต่ถ้าเรากำหนด configuration ให้ Pyro ใช้ feature Mobile code
เวลาที่ server เจอ code ที่ไม่รู้จัก มันก็จะ request code มายัง client
กรณี mobile code นี้ support 2-way
นั่นคือ support กรณี server return object ที่ไม่มี code บน client ด้วย
Related link from Roti
Sunday, May 25, 2008
ป้ายแดง
ช่วงนี้โรงเรียนลูกเปิดเทอมแล้ว
ผมก็เลยถอยรถคันใหม่ออกมาส่งลูกโดยเฉพาะ
เลือกรุ่น entry level (ราคาถูกกว่าคันของ ipats) พร้อมด้วยเบาะนั่งของเด็ก
ขี่ไปส่งลูกแล้วรู้สึกมั่นใจในความปลอดภัยขึ้นเยอะ

ส่วนคันเก่าก็ไม่ได้ทิ้งไปไหน พอส่งลูกเสร็จก็เปลี่ยนเป็นขี่เสือหมอบไปทำงาน
เพราะเจ้าเสือหมอบมันเร่งแซงได้ทันใจกว่ากันเยอะ
ผมก็เลยถอยรถคันใหม่ออกมาส่งลูกโดยเฉพาะ
เลือกรุ่น entry level (ราคาถูกกว่าคันของ ipats) พร้อมด้วยเบาะนั่งของเด็ก
ขี่ไปส่งลูกแล้วรู้สึกมั่นใจในความปลอดภัยขึ้นเยอะ

ส่วนคันเก่าก็ไม่ได้ทิ้งไปไหน พอส่งลูกเสร็จก็เปลี่ยนเป็นขี่เสือหมอบไปทำงาน
เพราะเจ้าเสือหมอบมันเร่งแซงได้ทันใจกว่ากันเยอะ
Related link from Roti
Friday, May 23, 2008
Case Class in Scala
ใครที่เคยเห็น code ของ Scala, คงต้องเคยเห็นคำว่า
ครั้งแรกที่ผมเห็นมัน ผมรู้สึกมึนตึบ แล้วก็สงสัยว่ามันคืออะไร
ทำไม case statement มาเกี่ยวอะไรกับ class ด้วย
หลังจากนั่งอ่าน Programming in Scala ของ Martin Odersky, Lex Spoon, Bill Venners
ก็เลยเกิดความกระจ่างขึ้น
เจ้า modifier "case" ข้างหน้า class นั้น มันทำให้ compiler ช่วย generate method บางอย่างเพิ่มขึ้นมา
เพื่อทำให้เราสามารถใช้ feature pattern matching กับ Object ได้ง่ายขึ้น
ในหนังสือเขายกตัวอย่าง กรณี expression
สมัยแรกๆที่ผมเห็น statement ข้างบน ผมก็จะนึกเดาไปว่า
ตัว case class มันต้องเขียนเรียงติดๆกันแบบเดียวกับพวก case statement
แต่จริงๆแล้วไม่ใช่ "case" เป็นแค่ modifiler (เหมือนพวก public, private, static ทำนองนั้น)
ประโยคข้างบนจริงๆแล้วก็คือ การประกาศ class ขึ้นมา 5 ตัว
ที่ดูแปลกๆ ก็คือใน scala กรณี empty body, เราไม่ต้องใส่ class body
สิ่งที่ case modifier ทำก็คือ
ดูเหมือนว่าสิ่งที่มัน gen ก็ไม่มีอะไรมาก
แต่ผลที่ได้ทำให้เราสามารถทำ pattern matching แบบนี้ได้
case classครั้งแรกที่ผมเห็นมัน ผมรู้สึกมึนตึบ แล้วก็สงสัยว่ามันคืออะไร
ทำไม case statement มาเกี่ยวอะไรกับ class ด้วย
หลังจากนั่งอ่าน Programming in Scala ของ Martin Odersky, Lex Spoon, Bill Venners
ก็เลยเกิดความกระจ่างขึ้น
เจ้า modifier "case" ข้างหน้า class นั้น มันทำให้ compiler ช่วย generate method บางอย่างเพิ่มขึ้นมา
เพื่อทำให้เราสามารถใช้ feature pattern matching กับ Object ได้ง่ายขึ้น
ในหนังสือเขายกตัวอย่าง กรณี expression
abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class UnOp(operator: String, arg: Expr) extends Expr
case class BinOp(operator: String, left: Expr, right: Expr) extends Expr
สมัยแรกๆที่ผมเห็น statement ข้างบน ผมก็จะนึกเดาไปว่า
ตัว case class มันต้องเขียนเรียงติดๆกันแบบเดียวกับพวก case statement
แต่จริงๆแล้วไม่ใช่ "case" เป็นแค่ modifiler (เหมือนพวก public, private, static ทำนองนั้น)
ประโยคข้างบนจริงๆแล้วก็คือ การประกาศ class ขึ้นมา 5 ตัว
ที่ดูแปลกๆ ก็คือใน scala กรณี empty body, เราไม่ต้องใส่ class body
{ } ให้มันก็ได้ (มันจะแอบใส่ให้เราเอง)สิ่งที่ case modifier ทำก็คือ
- compiler จะช่วย generate Factory method ที่ชื่อเดียวกับ class ให้เรา
ผลก็คือ เราสามารถใช้คำสั่งแบบนี้ได้val v = Number(10)
แทนที่จะเป็น
val v = new Number(10)
ซึ่งมีประโยชน์มากเวลาที่เรา nested แบบนี้
BinOp("+", Var("x"), Number(7)) - compiler จะช่วยทำให้ argument ทุกตัวกลายเป็น read only property ของ class นั้น
เช่น
scala> val b = BinOp("+", Var("x"), Var("x"))
b: BinOp = BinOp(+,Var(x),Var(x))
scala> b.operator
res23: String = + - compiler จะช่วย generate พวก method equals, hashcode ให้เรา
โดยตัว equals method มันจะ implement ในลักษณะที่จะเปรียบเทียบทุกๆ property ของ object ให้เรา
ทำให้เราสามารถเปรียบเทียบแบบนี้ได้
scala> Var("x") == Var("x")
res21: Boolean = true
scala> BinOp("+", Number(7), Number(8)) == BinOp("+", Number(7), Number(8))
res22: Boolean = true
ดูเหมือนว่าสิ่งที่มัน gen ก็ไม่มีอะไรมาก
แต่ผลที่ได้ทำให้เราสามารถทำ pattern matching แบบนี้ได้
def simplifyTop(expr: Expr): Expr = expr match {
case UnOp("-", UnOp("-", e)) => e // Double negation
case BinOp("+", e, Number(0)) => e // Adding zero
case BinOp("*", e, Number(1)) => e // Multiplying by one
case _ => expr
}
Related link from Roti
Wednesday, May 14, 2008
delegate ใน groovy closure
งาน NJUG ที่ผ่านมาตอนที่ฟังคุณ cblue พูดเรื่อง groovy
มีตัวแปรใน closure ตัวหนึ่งที่ผมติดใจ ก็คือ delegate
กลับมาแล้วก็เลยต้องนั่งเปิด groovy document หาความรู้เพิ่มเติม
ก็เลยเจอ snippet code ที่น่าสนใจตัวนี้เข้า
เทคนิคที่น่าสนใจก็คือการเปลี่ยน reference ของ delegate ให้ชี้ไปยัง object ที่เราต้องการ
ลองดูตัวอย่างการ run code ข้างบน
จะเห็นว่ามีการใช้ closure ซ้อนๆกัน
ทุกๆครั้งที่ มีการ execute inner closure ก็จะมีการ switch delegate ให้ชี้ไปที่
XmlBuilder Object แทนที่จะเป็น default parent object
มีตัวแปรใน closure ตัวหนึ่งที่ผมติดใจ ก็คือ delegate
กลับมาแล้วก็เลยต้องนั่งเปิด groovy document หาความรู้เพิ่มเติม
ก็เลยเจอ snippet code ที่น่าสนใจตัวนี้เข้า
เทคนิคที่น่าสนใจก็คือการเปลี่ยน reference ของ delegate ให้ชี้ไปยัง object ที่เราต้องการ
class XmlBuilder {
def out
XmlBuilder(out) { this.out = out }
def invokeMethod(String name, args) {
out << "<$name>"
if(args[0] instanceof Closure) {
args[0].delegate = this
args[0].call()
}
else {
out << args[0].toString()
}
out << "</$name>"
}
}
ลองดูตัวอย่างการ run code ข้างบน
จะเห็นว่ามีการใช้ closure ซ้อนๆกัน
def xml = new XmlBuilder()
xml.html {
head {
title "Hello World"
}
body {
p "Welcome!"
}
}
ทุกๆครั้งที่ มีการ execute inner closure ก็จะมีการ switch delegate ให้ชี้ไปที่
XmlBuilder Object แทนที่จะเป็น default parent object
Related link from Roti
Monday, May 12, 2008
Script bowl
หลังจากไป NJUG กลับมาผมพึ่งพบว่าใน java one มันมี event ที่ชื่อ Script Bowl
event นี้เป็นการจัดประชันระหว่าง script language 4 ตัวก็คือ JRuby, Groovy, Jython, Scala
โดยแบ่งการประชันออกเป็น 3 รอบ
รอบที่ 1 ให้ทำ app ที่เป็น Desktop GUI
รอบที่ 2 ให้ทำ app ที่เป็น Web Application
ส่วนรอบที่ 3 ให้ demo app อะไรก็ได้ที่คิดว่ามัน show feature ได้ถึงใจแฟนๆ
จากนั้นก็ให้ผู้ชมทำการ vote เข้ามา
ผลลัทพ์ที่ได้ ลองดูกันเองแล้วกัน
A คือ Groovy, B คือ JRuby, C คือ Jython, D คือ scala
Script Bowl Result
seapegasus เขาเขียนบรรยายเหตุการณ์โดยคร่าวๆไว้ที่นี่
Groovy, JRuby, Jython, Scala: Who Wins the Script Bowl?
event นี้เป็นการจัดประชันระหว่าง script language 4 ตัวก็คือ JRuby, Groovy, Jython, Scala
โดยแบ่งการประชันออกเป็น 3 รอบ
รอบที่ 1 ให้ทำ app ที่เป็น Desktop GUI
รอบที่ 2 ให้ทำ app ที่เป็น Web Application
ส่วนรอบที่ 3 ให้ demo app อะไรก็ได้ที่คิดว่ามัน show feature ได้ถึงใจแฟนๆ
จากนั้นก็ให้ผู้ชมทำการ vote เข้ามา
ผลลัทพ์ที่ได้ ลองดูกันเองแล้วกัน
A คือ Groovy, B คือ JRuby, C คือ Jython, D คือ scala
Script Bowl Result
seapegasus เขาเขียนบรรยายเหตุการณ์โดยคร่าวๆไว้ที่นี่
Groovy, JRuby, Jython, Scala: Who Wins the Script Bowl?
Related link from Roti
Sunday, May 04, 2008
ยืน-ไม่ยืน
สืบเนื่องจาก เรื่องสิทธิการไม่ยืนในโรงหนัง
ลองดูว่าที่อื่นๆเขามีประเด็นเกี่ยวกับเรื่องนี้อย่างไรบ้าง
แต่ที่ผมชอบคืออันนี้ (ซึ่งไม่เกี่ยวกับยืนไม่ยืน)
เพลงชาติอินเดีย สรรเสริญ King George V?
ส่วนตัวผมก็คิดว่าเราจะหา "สมดุล" ในเรื่องนี้อย่างไร
คือประโยชน์ของมันก็มี ไม่ใช่ไม่มี
แต่จะนำมันออกจากกรอบ "อำนาจนิยม" หรือ ความ"คลั่งไคล้" ได้อย่างไร
ลองดูว่าที่อื่นๆเขามีประเด็นเกี่ยวกับเรื่องนี้อย่างไรบ้าง
- เริ่มจากอเมริกา ดินแดนที่ประเทศไทยนับถือ
มีประเด็นเรื่องครูบังคับให้นักเรียนยืนเคารพเพลงชาติ - ต่อด้วยญี่ปุ่น (ซึ่งประเทศไทยนับถืออีกเช่นกัน)
ศาลตัดสินให้คุณครูไม่ยืนเคารพเพลงชาติได้ - ข้างบนนั้นเป็นกรณีชาติเดียวกัน แต่ถ้าเป็นคนละชาติหล่ะ ก็เป็นเรื่องสิ
เด็กนักเรียนอาหรับไม่ยืนเคารพเพลงชาติยิว
แต่ที่ผมชอบคืออันนี้ (ซึ่งไม่เกี่ยวกับยืนไม่ยืน)
เพลงชาติอินเดีย สรรเสริญ King George V?
ส่วนตัวผมก็คิดว่าเราจะหา "สมดุล" ในเรื่องนี้อย่างไร
คือประโยชน์ของมันก็มี ไม่ใช่ไม่มี
แต่จะนำมันออกจากกรอบ "อำนาจนิยม" หรือ ความ"คลั่งไคล้" ได้อย่างไร
Related link from Roti
Friday, May 02, 2008
this ใน javascript กับ dojo.hitch
ใน javascript, bug ที่พบกันบ่อยๆ ก็คือ scope ของ this ที่มักไม่ได้เป็นไปตามที่ programmer คิด
ยกตัวอย่าง
ถ้าลอง run code ข้างบนนี้ดู ก็จะพบว่า ถ้าเรา click link นั้นเมื่อไร
message ที่แสดงใน alert มันจะแสดงคำว่า "undefined" แทนที่จะเป็น 'hi'
ที่เป็นเช่นนี้ก็เพราะว่า this object ใน function debug ณ ขณะที่เกิด event
function มันจะเปลี่ยน scope ทำให้ this กลายเป็น DOM element ของ anchor แทนที่จะเป็น object foo
แล้ว dojo.hitch หล่ะคืออะไร
function นี้ในแง่ของ functional language ถือว่ามันเป็น higher order function
เนื่องจากมันเป็น function ที่ return function
หน้าที่หลักของ dojo.hitch ก็คือการ bind scope ของ function เข้ากับ object ที่เราต้องการ
อย่างตัวอย่างข้างบน ถ้าเรานำ dojo.hitch มาช่วย ก็จะเขียนเป็นแบบนี้แทน
ถ้าลอง run ดู ก็จะได้ message 'hi' ขึ้นมา
จะเห็นว่า hitch ช่วยเราเปลี่ยน scope ของ this จากเดิมที่เป็น DOM element (ที่ trig event นั้น) ให้กลายเป็น foo object แทน โดยใช้ technique การ binding
ลองมาดู code ของ function hitch กัน
เริ่มต้นด้วย การข้าม case กรณี arguments > 2 ไปก่อนเลย
อันนั้นเป็นเงื่อนไขพิเศษ กรณีที่ต้องการให้มี fixed(prefix) arguments.
ส่วนถัดมาก็คือส่วน ตรวจสอบว่า มีการ pass parameter มาตัวเดียวหรือเปล่า
ถ้ามาตัวเดียว ก็จะถือว่า parameter นั้นเป็น method
สุดท้ายก็ตรวจสอบอีกว่า method เป็น string
หรือเป็น string ก็จะ return closure ที่ห่อคำสั่ง scope[method].apply
ถ้าไม่ใช่ script ก็จะ return closure ที่ใช้คำสั่ง method.apply แทน
อืมม์พอเริ่มเข้าใจ ก็เริ่มเห็นความงาม
ถ้าใครสนใจอยากอ่านให้เข้าใจ(หรืองง)เข้าไปอีก อ่านเพิ่มเติมที่นี่
Jammastergoat - dojo.hitch
ยกตัวอย่าง
<a id='linkNode' href="#">link</a>
<script>
foo = {
greeting: 'hi',
debug: function() {
alert(this.greeting);
}
}
document.getElementById('linkNode').onclick = foo.debug;
</script>
ถ้าลอง run code ข้างบนนี้ดู ก็จะพบว่า ถ้าเรา click link นั้นเมื่อไร
message ที่แสดงใน alert มันจะแสดงคำว่า "undefined" แทนที่จะเป็น 'hi'
ที่เป็นเช่นนี้ก็เพราะว่า this object ใน function debug ณ ขณะที่เกิด event
function มันจะเปลี่ยน scope ทำให้ this กลายเป็น DOM element ของ anchor แทนที่จะเป็น object foo
แล้ว dojo.hitch หล่ะคืออะไร
function นี้ในแง่ของ functional language ถือว่ามันเป็น higher order function
เนื่องจากมันเป็น function ที่ return function
หน้าที่หลักของ dojo.hitch ก็คือการ bind scope ของ function เข้ากับ object ที่เราต้องการ
อย่างตัวอย่างข้างบน ถ้าเรานำ dojo.hitch มาช่วย ก็จะเขียนเป็นแบบนี้แทน
document.getElementById('linkNode').onclick = dojo.hitch(foo, "debug");
ถ้าลอง run ดู ก็จะได้ message 'hi' ขึ้นมา
จะเห็นว่า hitch ช่วยเราเปลี่ยน scope ของ this จากเดิมที่เป็น DOM element (ที่ trig event นั้น) ให้กลายเป็น foo object แทน โดยใช้ technique การ binding
ลองมาดู code ของ function hitch กัน
dojo.hitch = function(scope, method){
if(arguments.length > 2){
return dojo._hitchArgs.apply(dojo, arguments); // Function
}
if(!method){
method = scope;
scope = null;
}
if(dojo.isString(method)){
scope = scope || dojo.global;
if(!scope[method]){ throw(['dojo.hitch: scope["', method, '"] is null (scope="', scope, '")'].join('')); }
return function(){ return scope[method].apply(scope, arguments || []); };
}
return !scope ? method : function(){ return method.apply(scope, arguments || []); };
}
เริ่มต้นด้วย การข้าม case กรณี arguments > 2 ไปก่อนเลย
อันนั้นเป็นเงื่อนไขพิเศษ กรณีที่ต้องการให้มี fixed(prefix) arguments.
ส่วนถัดมาก็คือส่วน ตรวจสอบว่า มีการ pass parameter มาตัวเดียวหรือเปล่า
ถ้ามาตัวเดียว ก็จะถือว่า parameter นั้นเป็น method
สุดท้ายก็ตรวจสอบอีกว่า method เป็น string
หรือเป็น string ก็จะ return closure ที่ห่อคำสั่ง scope[method].apply
ถ้าไม่ใช่ script ก็จะ return closure ที่ใช้คำสั่ง method.apply แทน
อืมม์พอเริ่มเข้าใจ ก็เริ่มเห็นความงาม
ถ้าใครสนใจอยากอ่านให้เข้าใจ(หรืองง)เข้าไปอีก อ่านเพิ่มเติมที่นี่
Jammastergoat - dojo.hitch
Related link from Roti
Tuesday, April 29, 2008
What is programming.
ลอกมาจาก Programming 's Stone บทที่ 2
Ada is sitting in a room. In the evening the room becomes dark. Ada turns on the light.
That is the fundamental act of programming. There is a problem domain (the room), which is dynamic (gets dark). There is order to the dynamic problem domain (it will be dark until morning), permitting analysis. There is a system that can operate within the problem domain (the light), and it has semantics (the switch state).
There is a desire (that the room shall remain bright), and there is an insight (that the operation of the switch will fulfill the desire).
Dynamic problem domains, systems and semantics are covered in detail elsewhere.
Related link from Roti
Subscribe to:
Comments (Atom)




{kind=link}