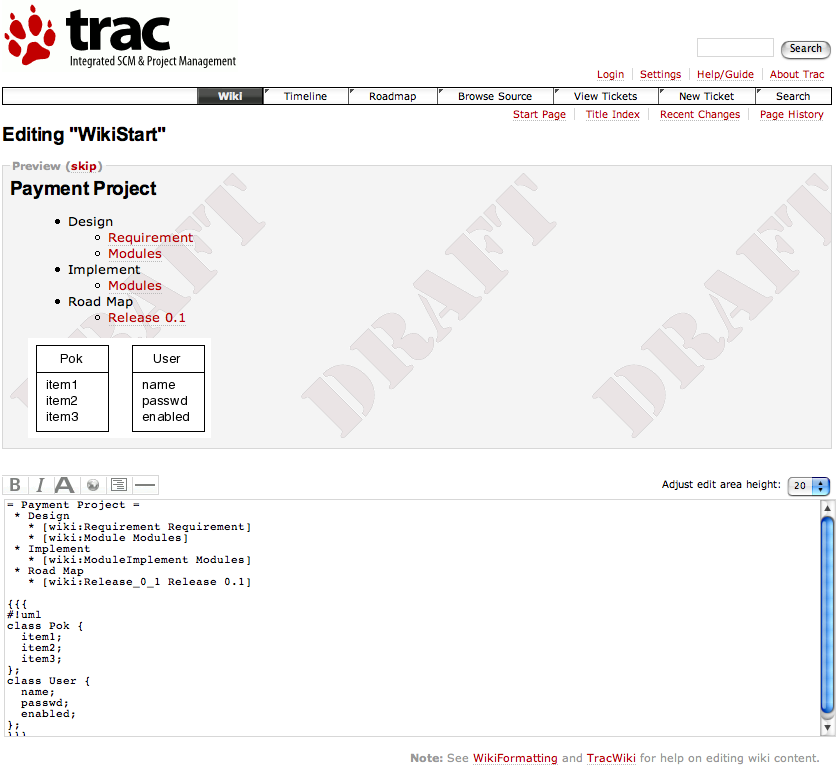
ที่เรากำหนดให้กลายเป็น syntax ของ graphviz ไปแล้ว
ตอนนี้จะดูว่า การ implement plugin ใน trac ต้องทำอย่างไร
ถ้าเราดูเอกสาร Trac Component Architecture
จะเห็นว่า Trac design architecture ในลักษณะเดียวกับ
Eclipse Plugin (ซึ่ง base จาก osgi framework อีกที)
model ของ Trac plugin

model ของ eclipse plugin
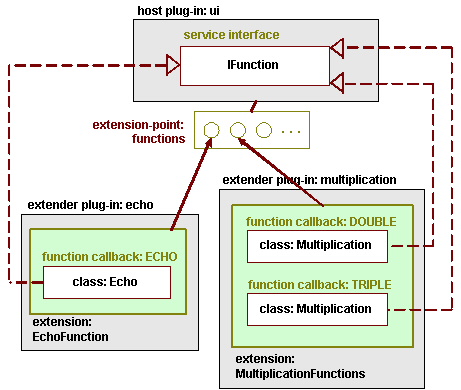
ดังนั้นการที่เราจะ implement plugin ของเราขึ้นมา
เราก็ต้องรู้ก่อนว่า plugin ของเรา จะ integrate เข้ากับ extension point
อะไร
ในกรณีของเรา เราต้องการทำเป็น wiki macro
ดังนั้น extension point ของเราก็คือ
trac.wiki.api.IWikiMacroProvider
code ของเรา ก็ต้องเริ่มต้นด้วย
class UmlMacro(Component):
implements(IWikiMacroProvider)
def __init__(self):
self.log.info("UmlMacro start")
self.parser = Parser();
def get_macros(self):
yield 'uml'
def get_macro_description(self, name):
return "Use this macro for render class diagram"
จะเห็นว่ามีการ call implements function ที่ชื่อ IWikiMacroProvider
method หลักๆที่ต้องเขียนมีอยู่ 3 อันคือ
- get_macros
ต้อง return เป็น iterable - get_macro_description
- render_macro
อันนี้เป็นส่วน implement การทำงานจริง โดยมีการ pass ค่า
content (ซึ่งเป็น string ที่เราต้องแปลง) เข้ามา
ประเด็นถัดไปก็คือ uml plugin ของเรา
ไม่ต้องการ เรียก graphviz process เอง
แต่อยากส่งต่อให้ graphviz plugin ไปทำงานต่อ
ตรงนี้ใช้เวลาหาอยู่เกือบ 2 ชั่วโมง
ตอนแรก พยายามใช้ผ่าน plugin manager
แต่หาวิธีเรียกไม่ได้สักที
สุดท้ายก็ไปปิ๊ง idea ว่า ในเมื่อมันเป็น plugin architecture
เราก็เรียกมันผ่านทาง extension point นั่นแหล่ะ
วิธีการก็คือ
def render_macro(self, req, name, content):
wiki = WikiSystem(self.env)
for provider in wiki.macro_providers:
if "graphviz" in list(provider.get_macros()):
return provider.render_macro(req, "graphviz",
self.parser.parse(content).to_dot())
return "none"
เริ่มด้วยการ new WikiSystem (คิดว่ามันเป็น singleton pattern นะ)
แล้วเรียกหา macrosprovider list มา
เพื่อทำการ iterate หา Graphviz Plugin Provider
เมื่อได้มา ก็แค่ส่งต่อ syntax ที่เราใช้ parser แปลงไว้แล้วไป
สรุป
===
Trac มีการออกแบบโครงสร้าง Architecture ไว้ดีมาก
code python ที่เขียนไว้ ก็อ่านทำความเข้าใจง่าย
น่าสนใจที่นำมาใช้เป็นแกนหลัก ในการทำ project management
ส่วน shot ถัดไป
ผมกำลังมองเรื่องการ integrate mylar เข้ากับ trac