วันนี้อ่านเจอใน Planet Eclipse ว่า
site eclipse.org จะปรับปรุง search engine ใหม่
โดยจะปรับปรุงกฎการให้น้ำหนัก
ที่น่าสนใจก็คือ เขาบอกด้วยว่า เขาใช้
mnoGoSearch เป็น search engine
ก็เลยตามไปดูสักหน่อย
ตัว mnoGoSearch เป็น search engine ที่ใช้ database table
ในการทำ index (lucene ใช้ file system)
ตัวมันประกอบด้วย 2 ส่วนคือ
- Indexer ที่ใช้ scan web document เพื่อทำ index
- CGI front-end ที่ใช้ในการ search
ที่น่าสนใจ ก็คือ mnoGoSearch support ภาษาไทย ด้วย
โดยมี dictionary thai มาให้ด้วย โดยมีจำนวนศัพท์มาให้ 32895 คำ
ในขั้นตอนการทำ index เราสามารถ config
ให้มัน scan web site ได้หลายลักษณะ เช่น
- page scan เฉพาะ page ที่ระบุ
- path scan เฉพาะ document ที่อยู่ใต้ path ที่ระบุ
- site scan documents ที่อยู่ใน host นั้น
- world scan any document
ตัวอย่างเช่น
# To index whole server "localhost":
Server http://localhost/
#
# You can also specify some path to index subdirectory only:
Server http://localhost/subdir/
#
# To specify the only one page:
Server page http://localhost/path/main.html
ผมไม่ค่อยสนใจ feature ที่ใช้ scan static web site เท่าไร
ที่สนใจก็คือ feature ที่สามารถใช้ scan database table ได้โดยตรงมากกว่า
ตัว mnoGoSearch มี protocol ที่เรียกว่า
HTDB สำหรับทำแบบนี้
ลักษณะการทำงาน เป็นดังนี้
- ระบุ connection ที่จะใช้ต่อ database (dbname, user, password)
- select primary key ของ table ที่เราต้องการ scan ขึ้นมาทั้งหมด
- กำหนด select ที่ทำให้ได้เนื้อหาของข้อมูลที่เราต้องการทำ index
ลองดูตัวอย่าง
HTDBAddr mysql://user:passwd@localhost/dbname/?dbmode=single
เริ่มด้วยการระบุ database
HTDBList "select id from snippets"
ในที่นี้เราต้องการทำ index บน table snippets
HTDBDoc "select concat('HTTP/1.0 200 OK\\r\\n', 'Content-type: text/plain;charset=utf-8\\r\\n', 'Content-Language: th\\r\\n','\\r\\n', description) from snippets where id = $1 "
จากนั้นก็ระบุ sql ที่ทำให้ได้เนื้อหาที่ต้องการทำ index
โดย mnoGoSearch จะ pass primary key เข้ามาให้
ในชื่อตัวแปร
$1จะเห็นได้ว่าเราต้องแปลงเนื้อหาของเรา
ให้อยู่ในรูปแบบของ http response เสียก่อน
key ที่สำคัญตัวที่หนึ่งก็คือ การระบุ language
ไม่งั้นมันจะพยายามเดา language ให้เอง
ส่วนตัวที่ 2 ก็คือการระบุ encoding ที่ใช้
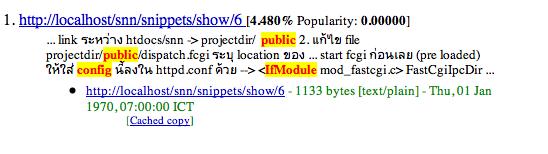
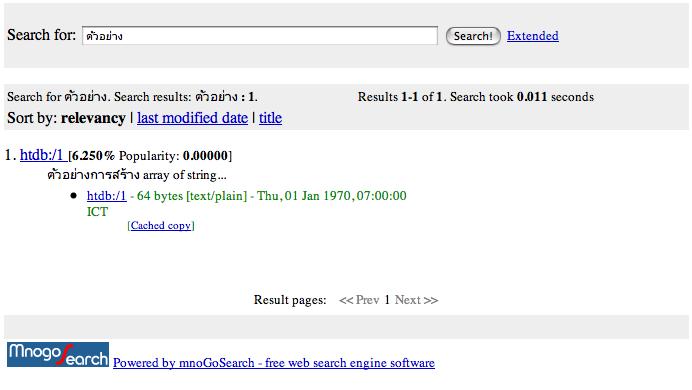
ส่วนรูปข้างล่างนี้เป็น screen dump หน้าจอ search ของ mnoGoSearch

จะเห็นได้ว่า ผลลัพท์ที่เราได้จะมี url ในรูปของ htdb:/nn
ตัวเลข nn ก็คือ primary key ของ row ที่ search เจอนั่นเอง
ในส่วนของการ scan static web site นั้น
เท่าที่ลองใช้ดู ทดลอง scan 2 ที่นี้ดู
Server page http://www.pantip.com/cafe/index.html
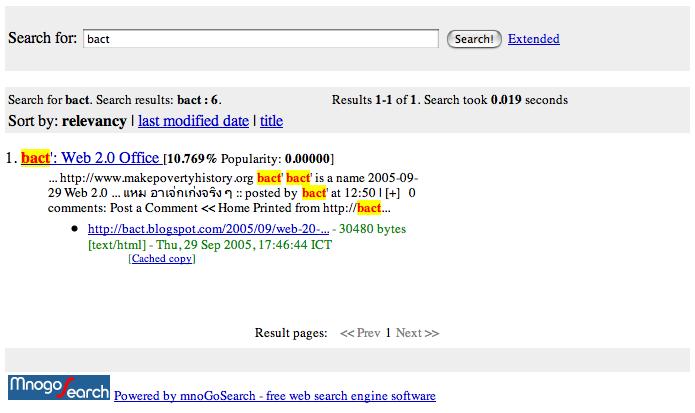
Server page http://bact.blogspot.com/2005/09/web-20-office.html

ของ pantip ทำ index ออกมาได้ ทดลองค้นหาดู
พบว่าคำบางคำ ก็ค้นเจอ บางคำก็ไม่เจอ
เช่น ถ้าใช้คำว่า"ห้องสมุด" จะเจอ ส่วนคำว่า "ไกล", "ไกลบ้าน"
นั้นหาไม่เจอ แต่ถ้าเปลี่ยนเป็น "บ้าน" เฉยๆ ก็จะเจอ

ส่วนของ bact จะเห็นว่าอ่านภาษาไทยมาถูกต้อง
แต่ search ด้วยภาษาไทยไม่เจอเลย
ไปดูใน datadict ของ mnoGoSearch มันระบุว่า
site นี้ Content-Language เป็น ภาษาอังกฤษ (en)
ก็เป็นไปได้ว่ามันเดาภาษาผิด ก็เลยไม่ได้เอา dict ไทยไปจับ