ในที่สุด ก็รอไม่ไหว หันไปหาทางเลือกอื่น
นั่นคือ ช่องทาง ODBC
solution ก็คือ
- unixODBC
อันนี้ไม่มีอะไรพิเศษ ติดตั้งได้จากพวก Package Manager ของ Distro ได้เลย
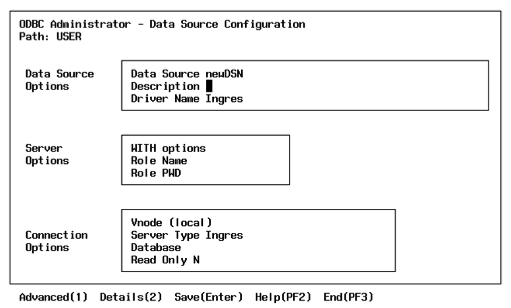
ประเด็นถัดมา ก็คือการสร้าง datasource
ถ้าสร้างด้วยมือ ดูจะโหดร้ายไปหน่อย
ingres ก็เลยเตรียม utility ที่ชื่อiiodbcadmn
- Ruby ODBC
ตัวนี้มีปัญหานิดหน่อย
ตรงวิธีที่เขาเขียน
เนื่องจากเขาเขียนโดยอิง mysql เป็นหลัก
พอมาใช้กับ database ตัวอื่น ก็อาจจะเป็นปัญหาบ้าง
ในกรณีของ ingres ถ้าลอง build แล้ว run testcase ดูจะพบ error นี้[pphetra@fedora ruby-odbc-0.9991]$ ruby test.rb sso
connect.............ok
create_table........ok
insert.............../test/20insert.rb:6:in `call': 37000 (2913)
[unixODBC][Ingres][Ingres ODBC Driver][Ingres]line 1, You cannot assign
a value of type 'varchar' to a column of type 'integer'.
Explicitly convert the value to the required type. (ODBC::Error)
from ./test/20insert.rb:6
from test.rb:20
from test.rb:16
ถ้าเข้าไปดูใน testcase จะเห็น code ที่มีปัญหา หน้าตาเป็นแบบนี้$p = $c.proc("insert into test (id, str) values (?, ?)") {}
$p.call(3, 'FOO')
ประเด็นที่เป็นปัญหา ก็คือวิธีที่ใช้ในการ binding parameter เข้ากับ statement
หลังจากไล่ source code ของ ruby-odbc ซักพัก ผมก็เจอจุด quickfix
ก็เลยแก้ง่ายๆลงไป@@ -6265,6 +6266,7 @@
if (coldef == 0) {
switch (ctype) {
case SQL_C_LONG:
+ stype = SQL_NUMERIC;
coldef = 10;
break;
case SQL_C_DOUBLE: - Ruby DBI
ตัวนี้ไม่มีอะไรพิเศษ
ผมเลือกลงแต่ dbd ที่ต่อเข้า ODBC อย่างเดียว
ขั้นตอนถัดไป ระหว่างรอให้มี ODBC Adapter(สำหรับ rails) ดีๆออกมา
ก็จะทดลองเขียน rails adapter ที่ต่อเข้ากับ ruby dbi ไปพลางๆก่อน
(ใช้ตัวอย่างจาก sqlserver adapter ที่มี mode ที่ใช้ odbc ด้วย)


