ที่ใช้ในการตรวจสอบ word ที่เข้ามาว่าถูกต้องตรงใน dictionary หรือไม่
กรณีไม่ถูก ก็สามารถ suggest คำที่ไกล้เคียงที่สุดให้ได้ด้วย
โดยส่วนใหญ่เรามักจะใช้ algorithm minimum edit distance
ในการ solve หาคำที่ไกล้เคียงที่สุด แต่ใน SpellChecker นี้
ใช้ technique ที่เรียกว่า n-gram
การใช้งาน SpellChecker จะเริ่มต้นด้วยการ create Index ที่จะใช้ search ก่อน
โดย index นี้ใช้ api ของ lucene ในการสร้างขึ้นมา
ส่วนข้อมูลที่จะป้อนเข้าไปเก็บใน index นี้จะต้องป้อนผ่าน
Dictionary ซึ่งทาง SpellChecker เตรียม Dictionary
มาให้เรา 2 แบบคือ
- PlainTextDictionary
ใช้กับ input word ที่อยู่ในรูป Text File - LuceneDictionary
ใช้กรณีที่เราต้องการ extract word มาจาก lucene index ที่มีอยู่แล้ว
ตัวอย่างการสร้าง index
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.search.spell.Dictionary;
import org.apache.lucene.search.spell.LuceneDictionary;
import org.apache.lucene.search.spell.SpellChecker;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
...
IndexReader reader = null;
try {
Directory indexdir = FSDirectory.getDirectory("/tmp/luceneIndex", false);
Directory spellIndex = FSDirectory.getDirectory("/tmp/spellChecker", true);
reader = IndexReader.open(indexdir);
Dictionary dict = new LuceneDictionary(reader, "name");
SpellChecker spellChecker = new SpellChecker(spellIndex);
spellChecker.indexDictionnary(dict);
} finally {
if (reader != null) {
reader.close();
}
}
ข้อมูลที่เก็บไว้ใน index จะแยกเก็บเป็น 1 document(lucene document)
ต่อ 1 word ที่ป้อนเข้าไป
สมมติว่าเรามี word "พระโขนง" เจ้า SpellChecker จะเก็บเป็น index ดังนี้
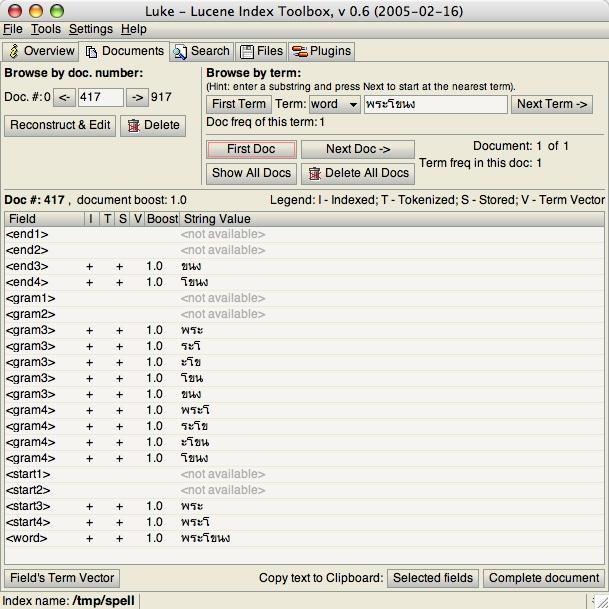
เห็นได้ว่ามีการใช้ 3-gram กับ 4-gram เป็นหลักเนื่องจากคำนี้มีความยาวมากพอ
โดยจะแบ่งออกเป็น 4 ส่วนคือ start, gram, end, word
ส่วนกรณีการ search หา ก็สามารถทำได้ดังนี้
กรณีที่ตรวจว่ามีคำนี้ใน Spell Dict. ของเราหรือไม่ ก็ใช้คำสั่งนี้
Directory spellIndex = FSDirectory.getDirectory("/tmp/spell", false);
SpellChecker spell= new SpellChecker(spellIndex);
spell.exist("พระโขนง");
Note: SpellCheck จะใช้ method ของ lucene ที่ชื่อ
docFreqในการ search แบบนี้
ส่วนกรณีที่ต้องการหา word ที่คล้ายกันก็ใช้คำสั่งนี้
(เลข 2 คือ parameter ที่บอกว่าต้องการ similar word แค่ 2 ตัวพอ)
String[] strs = spell.suggestSimilar("พระโขง", 2);
results:
พระโขนง
พระแสง
ขั้นตอนการทำงานภายใน ของ
suggestSimilarจาก word ที่เข้ามา SpellChecker จะจัดการสร้าง Boolean Query ที่มี query แบบนี้
start3:พระ^2.0
gram3:ระโ
gram3:ะโข
end3:โขง
start4:พระโ^2.0
gram4:ระโข
end4:ะโขง
จะเห็นได้ว่า startN จะถูก boost ด้วย 2
ถ้าลองดูผลลัพท์ที่ได้ จะเห็นว่าได้มาเยอะเชียว (ตัวอย่างข้อมูลที่ใช้เป็น dictionary
ของ อำเภอทั่วประเทศ)
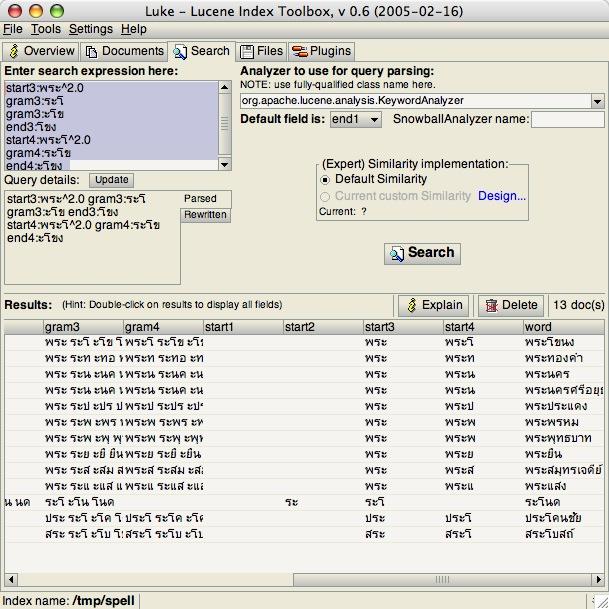
จากนั้นผลการ search ที่ได้ จะถูกคำนวณ score ด้วย algorithm Levenshtein distance
และเรียงลำดับก่อน return กลับมาให้ผู้ใช้
อ่านเพิ่มเติม



2 comments:
เจ๋งอ่ะ
ขอสอบถามหน่อยครับ
ผมลองสร้างโดยใช้ SpellChecker แล้วมันสร้าง fields ต่างๆ ตาม algorith NGram นะครับ แต่ตรง String Value มันไม่มีค่าครับ ผมต้องไปนั่ง rebuild ใหม่ใน Luke อ่ะครับ
ตรงนี้พอมีวิธีแก้ไหมครับ
ผมใช้ lucene 2.3.2
Luke 0.8
ครับ
Post a Comment