เจ้า database ตัวนี้เป็นงานวิจัยของ "The Institute for Mathematics and Computer Science Research of The Netherlands"
ออกแบบสำหรับ "high performance on complex queries against large databases" โดยเฉพาะ
ประเด็นที่น่าสนใจของ Monet ก็คือเรื่องของการ Design Storage
เจ้า Monet เลือกวิธีการเก็บ table structure ในลักษณะของ
BAT (Binary Association Tables)
ปกติ database ทั่วไป เวลาที่เก็บข้อมูลจะมองข้อมูล เป็น row
แต่ละ column ใน row หนึ่งจะเก็บอยู่ใน segment เดียวกัน
แต่เจ้า MonetDB เลือกที่จะ split Table หนึ่งออกเป็นหลายๆ BAT
โดยแต่ละ BAT จะเก็บข้อมูลแค่ 1 column เท่านั้น (จริงๆแล้วต้องเป็น
2 เพราะจะมีอีก column หนึ่งจะใช้เก็บ oid (object id))
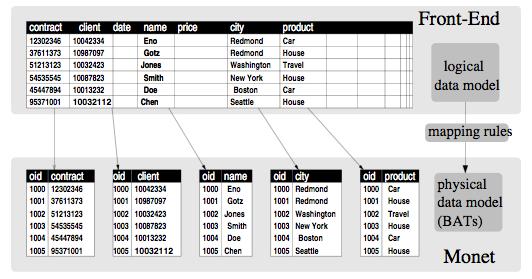
การเก็บในลักษณะนี้เหมาะสำหรับงานพวก OLAP, Data Mining
หรืองานที่มี nature ของ sql ในลักษณะของการ scan column
เป็นอย่างมาก
Note: บางคนอาจจะสงสัยต่อไปว่า ถ้าเก็บข้อมูลในแบบ BAT แบบนี้
น่าจะเปลืองเนื้อที่ของ harddisk เพราะว่ามี OID ที่ซ้ำๆกันอยู่เต็มไปหมด
เจ้า MonetDB ก็เลยออกแบบให้ oid เป็น virtual column
ไม่มีการเก็บจริง โดยให้ค่าของ oid เริ่มต้นที่ 1000 เรียงไปเรื่อยๆ
ไม่มีการกระโดด กรณีทีต้องการ access BAT ที่ oid=1002
ก็หมายถึง record ในตำแหน่งที่ 2 (1002 ลบด้วย 1000)
หลังจากเห็น concept แล้วก็ลอง load source code มา build ดู
หลังจากลองมั่วอยู่สักพัก ก็ได้ข้อสรุปว่า ยังไม่น่าประทับใจนัก
ไม่แน่ใจว่าเป็นเรื่อง platform ด้วยหรือเปล่า เพราะผม build
บน mac os x มันก็เลยมีปํัญหาประปรายไปหมด
เช่น connect jdbc แล้วสั่ง create user แล้วเงียบหาย
cpu ทำงานไป 15 นาทีแล้วยังไม่ return result กลับมา
หรือ ทดลอง load sample data สำเร็จ แต่ select
แล้วดัน error
ไว้มีเวลา จะลอง load binary version มาทดสอบบน
linux หรือ windows อีกที
จริงๆมีเรื่องน่าสนใจอีกเยอะ สนใจติดตามอ่านดูใน paper นี้
Monet: A Next-Generation DBMS Kernel For Query-Intensive Applications. Ph.D. Thesis, Universiteit van Amsterdam, Amsterdam, The Netherlands, May 2002.
Link
Note: อ่านดูใน paper นี้แล้วในส่วนของ introduction มี
ประวัติของ DBMS ที่น่าสนใจ เลยตัดมาให้อ่านกัน
The first widly known relational implementations (DBMS) were INGRES, developed at UC Berkeley and System R, developed at the IBM San Jose research facility.
INGRES was the first system to use UNIX as its implementation platform.It use the relational query language QUEL, that is not identical, yet very similar, to today's SQL. Several ideas from INGRES can still be found in current relational products, like the concept of a query rewriter for implementing views and integrity constraints, the use of relational tables to store meta-information (the data dictionary) and the idea of extensible query access methods. INGRES was commercialized into product, and from it the Sybase DBMS evolved, later to be re-marketd and enhanced into Microsoft SQLserver.
System R introduced many important concepts like the SQL query language, and much exemplary work in logging and recovery was done in the implementation of the lower levels of the system.
Parts of System R made it into various IBM products like QBE, SQL/DS and indirectly DB2. Although not based on its source code, the Oracle system was designed to resemble System R very closely.
The successor project to INGRES, call Postgres..... Postgres was further developed into a product called Illustra, which was shortly after integrated into the commercial Informix DBMS.
ปัจจุบัน Ingres เป็น opensource ไปแล้วนะครับ
สนใจ download ได้ที่นี่ Link
ยังใช้งานได้ดีที่เดียว



2 comments:
เนื้อหาดีมากครับ ผมอยากได้ข้อมูลประวัติความเป็นมาของMS Access(ทำวิจัย+วิทยานิพนธ์)สักหน่อยจะได้ไหมครับ
//Phasathorn802@hotmail.com
access ไม่ค่อยมีประวัติหวือหวาครับ
อ่านใน wikipedia ได้เลย
http://en.wikipedia.org/wiki/Microsoft_Access
Post a Comment